Kasten: магическая коробочка для ваших контейнеров

У нас в Russian Backup User Group уже не раз возникали споры на тему — а нужен ли контейнерам бекап? Давайте сегодня разберёмся — нужен ли он на самом деле и что предлагает Kasten как платформа в этом направлении.
Обычно аргументы против сводятся к тому, что контейнерная инфраструктура должна быть stateless, т.е. не сохранять данные внутри самого контейнера. Но я бы назвал это исключительно рекомендациями или best practice, которые далеко не всегда применяются на конкретных инфраструктурах. Так почему же нам нужен бекап?
- Когда контейнеры у нас не stateless, а stateful, т.е. данные по тем или иным причинам хранятся внутри контейнера. Но, когда мы говорим о хранении данных внутри контейнера, это не совсем верно. Данные хранят в Persistent Volumes — это внешняя сущность по отношению к самому контейнеру. При этом PV — это абстракция, с которой Kubernetes всегда работает по одному API, а вот чем PV реализуется — вопрос третий. Это может быть какая-то железная хранилка (через соответствующий CSI-драйвер) или какое-нибудь распределенное хранилище, типа Ceph или Linstor. Так как же нам зебакапить базу? Да ещё и сделать это консистентно? Через бекап самого PV, соответственно, и нужно, чтобы была возможность сообщить самой базе о необходимости сбросить данные на диск или чего-то ещё.
- Внутри Kubernetes для многих контейнеров у нас есть ещё различная обвязка не связанная непосредственно с данными — конфиги, сертификаты, ключи шифрования и т.д.
- Давайте выйдем из рамок контейнера (ведь не только им ограничивается наша инфраструктура) — нэймспейсы, сети, всё это тоже стоит бекапить.
Конечно то, что указано в пунктах 2 и 3 можно задеплоить с нуля и получить такую же рабочую среду, но во многих случаях восстановление этих сущностей из резервной копии будет быстрее и мы будем точно уверены, что восстановили рабочую конфигурацию в которую за время её существовать могли вноситься изменения, которые не отражены в наших yaml для деплоя.
Пожалуй, наибольшую проблему вызывает как раз первый пункт, когда контейнеры stateful. Внутри контейнера мы имеем какие-то данные и в случае аварийной ситуации, если проблема произошла с конкретным контейнером, мы можем задеплоить его с нуля и подключить к тем же данным, но что если проблема случилась с самим хранилищем? Или если всё работает корректно, но произошла проблема с самими данными?
Ещё один момент — миграция. Если со stateful всё понятно — переносить на другую площадку нужно не только сам деплоймент, но и данные — здесь вариантов сам Kubernetes нам никаких не предоставляет, только руками, соответственно, нам нужно будет остановить наш сервис на время миграции, либо после миграции на новую площадку наши данные уже могут быть устаревшими. Но даже если наши контейнеры не содержат данные, то миграция со своей инфраструктуры куда-то в публичное облако может вызвать затруднение ввиду различных конфигураций площадок, т.е. нужно будет внести изменения в деплоймент, который может быть довольно обширный и изменение конфигурации может занять продолжительное время.
И так, перейдём к Kasten (или Kasten K10, если бы точнее). Kasten продолжает следовать основной философии Veeam — резервное копирование не должно быть сложным. Платформа должна разворачиваться, настраиваться и поддерживаться максимально просто. Установка из репозитория Helm не должна вызывать трудностей, а настройка среды резервного копирования и политик резервирования Kubernetes должна занимать считанные минуты.
Поговорим про архитектуру. Kasten использует API для работы как с самими Kubernetes, так и с инфраструктурой, которая находится под ним, в частности — система хранения через Container Storage Interface (CSI), который по сути также является универсальным API, который поддерживается различными вендорами СХД — Ceph, Portworx, NetApp, Pure Storage и другими для унифицированной работы с хранилищами.

Это если рассматривать систему с точки зрения получения продуктивных данных. Но есть и обратная сторона, когда мы хотим перенести наши бекапы куда-то ещё. Тут также поддерживаются различные провайдеры, предоставляющие S3 хранилища, есть интеграция с репозиторием Veeam (со стороны Kasten это уже реализовано, осталось чтобы поддержка появилась в самом VBR и нам её уже даже показывали на VeeamOn 2021 — вероятнее всего она появится уже в 11-й версии или в одном из апдейтов к 10-й версии) и поддержка NFS (но NFS должен быть подключен к кластеру Kubernetes в качестве Persistent Volume).
В целом же, система выглядит таким образом.
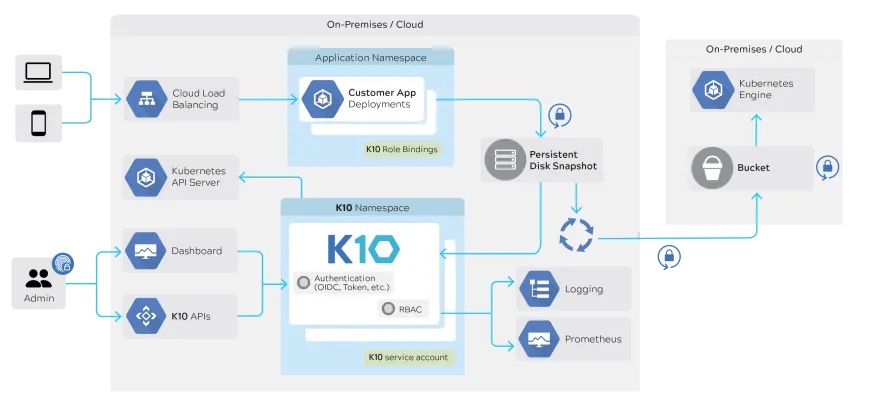
Ещё одно важное направление, которым занимается Kasten — Kanister. Выше я уже говорил о том, что резервное копирование контейнеров Kasten выполняет при помощи их снепшотов. Но если перед нами стоит задача защиты приложения, работающего с базой данных, то лучшим вариантов резервной копии может являться дамп этой базы. Kanister самостоятельно может определять приложения, работающие с БД и делать её дамп. Этот функционал отлично расширяет возможности Kasten.
Перейдём от теории к практике. Первым делом, после развёртывания нас встречает дашборд системы.
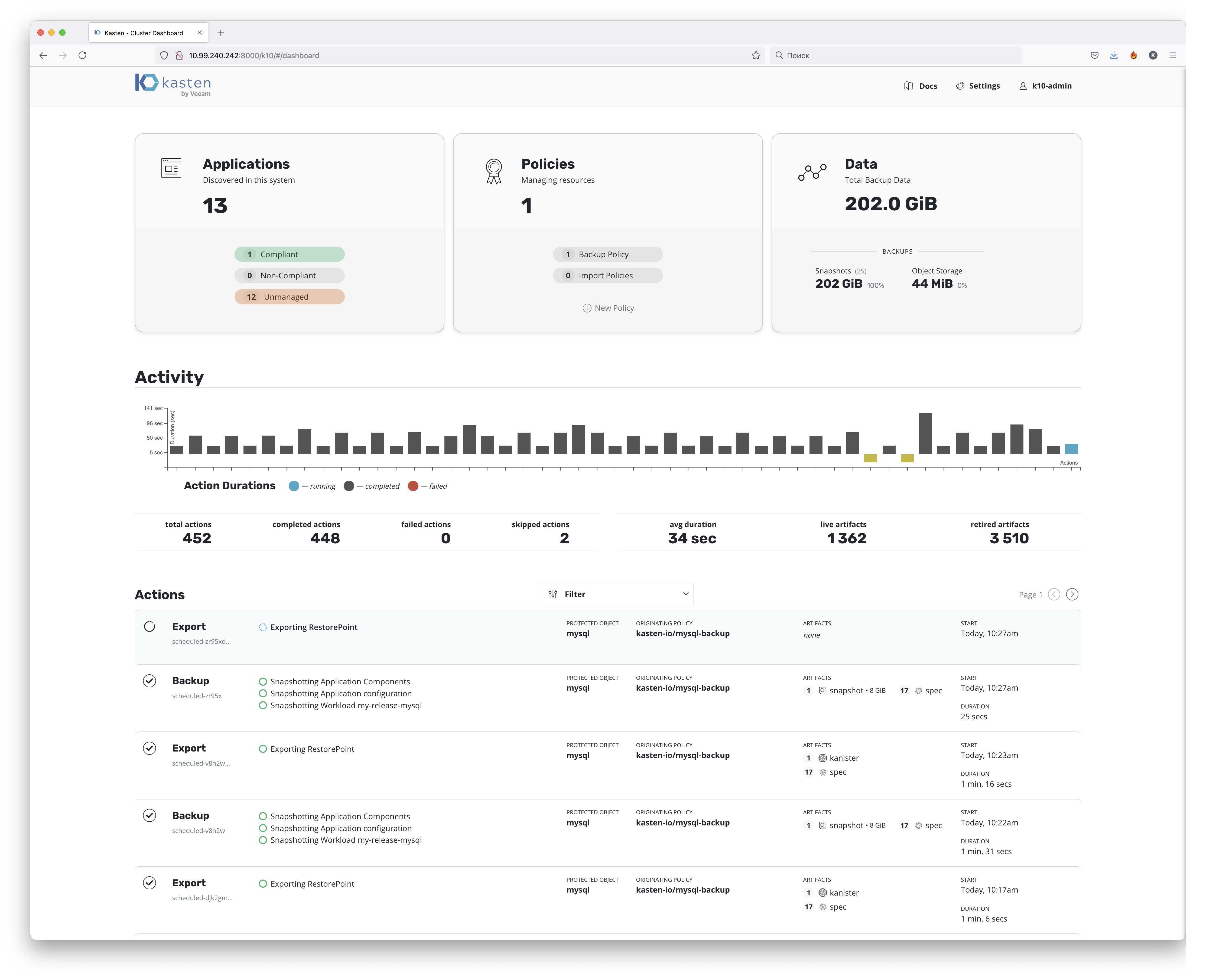
Я не любитель тёмных тем, но для желающих она так же присутствует. Сразу скажу — вы не обязаны использовать веб-интерфейс. Вообще контейнеризация приучает к консольке и работе с yaml, соответственно, и с Kasten вы можете работать через них. Но начнём обзор мы всё таки с интерфейса. А он довольно прост.
Первые 3 большие плашки отвечают за:
- Приложения — это те приложения, которые развёрнуты в нашем кластере Kubernetes. Kasten их может обнаруживать самостоятельно и демонстрирует какие приложения у нас соответствуют политикам резервирования, какие нет, а какие вообще не имеют политик.
- Политики — резервное копирование приложений на основе Kasten построено на политиках. Все политики вы создаёте и настраивает для каждого приложения так, как этого требуют ваши задачи.
- Занимаемый объём нашими копиями. Копии могут быть 2 видов. Первый — это просто снепшоты, которые хранятся в рамках самого кластера. Второй — это экспорт данных во внешнее хранилище. Экспорт — важная вещь, т.к. хранение снепшотов внутри кластера не даёт гарантии сохранности данных. Также как и в случае со снепшотом ВМ или снепшотом луна — снепшот привязан к своему «родителю» и в случае его удаления или недоступности данных снепшот тоже будет недоступен. Но если мы делаем его экспорт во внешнее хранилище, то он уже не связан с оригинальным контейнером и мы можем из него восстановиться даже в случае потери контейнера (и данных внутри него).
Следующие разделы — Activity и Actions демонстрируют саму работу наших политик — когда и сколько выполнялись, что именно было сделано.
И по большому счёту это всё, что у нас есть. Конечно же все эти разделы сопровождаются пачкой настроек, но по сути, это всё, что нам нужно, для того чтобы настроить резервное копирование приложений в нашем кластере. Проще даже не знаю что может быть. Даже проще, чем Veeam версии 9 🙂
На самом деле уже из коробки Kasten полностью готов к работе. Но вначале я рекомендую обратиться к разделу настроек
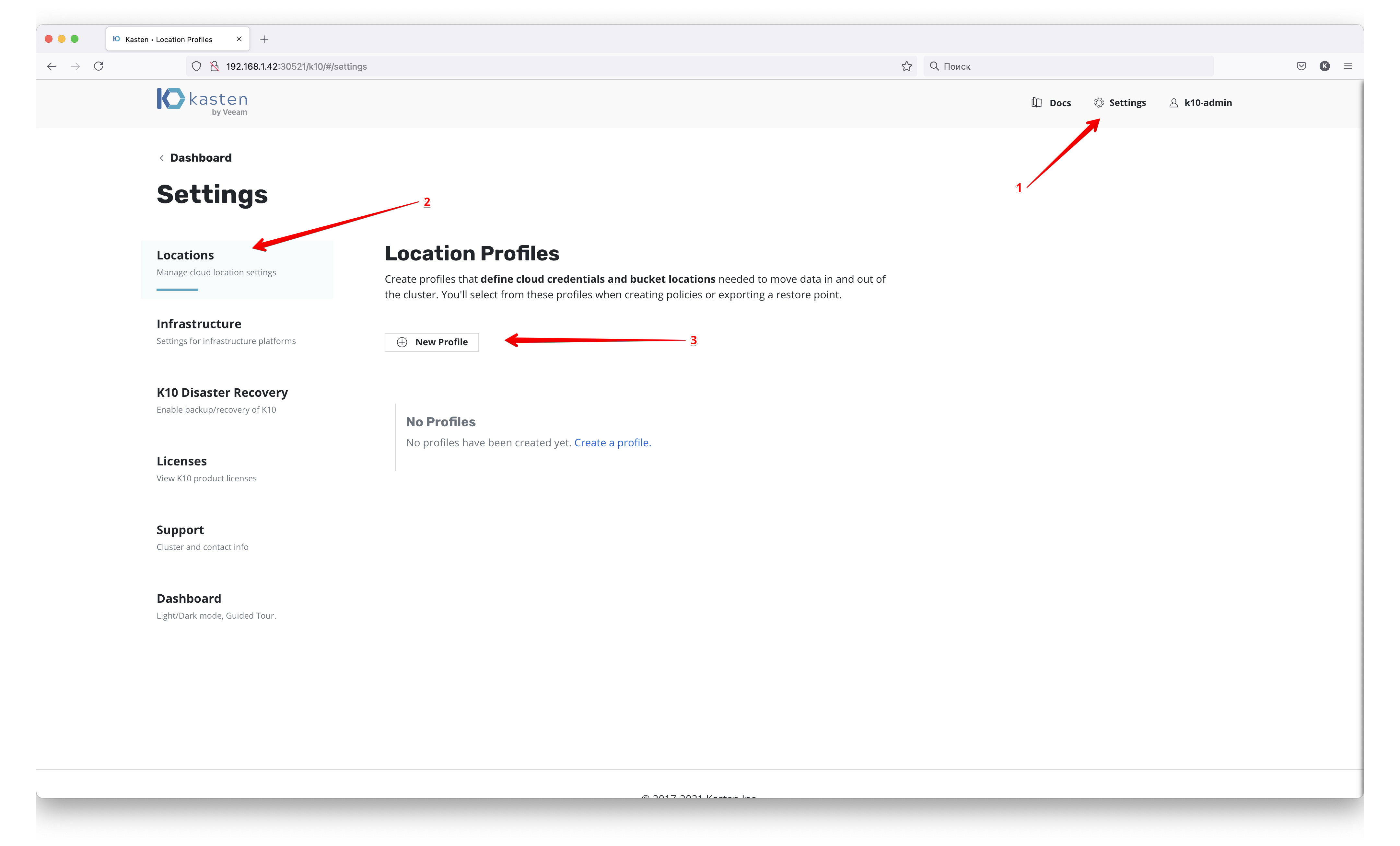
чтобы настроить внешнее хранилище для наших резервных копий, т.к. хранить их только в рамках продуктивного кластере крайне нехорошо. Здесь стоит уточнить — работа Kasten строится на снепшотах PV, и в большинстве случаев эти снепшоты хранятся вместе с оригинальным контейнером. Поэтому хранение их вместе с продуктивом ведёт к потере в том числе и бекапов, в случае отказа основного хранилища. Но не всегда это так, например в AWS снепшоты контейнеров всегда хранятся в их S3 хранилище.
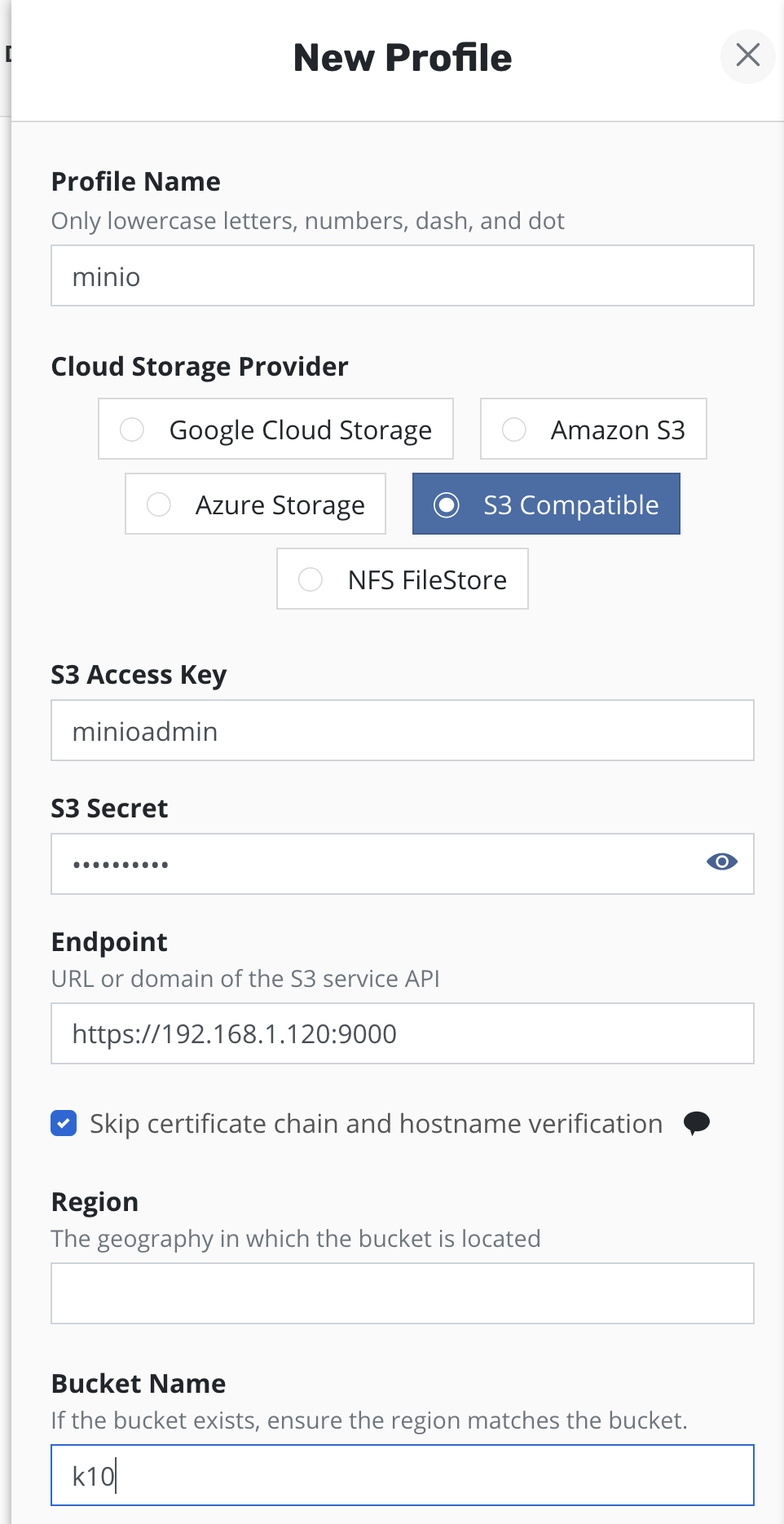
Как я уже говорил ранее — это может быть как облачное хранилище гиперскейрела, так и ваше собственное S3 совместимое хранилище, либо же NFS шара и в будущем будет добавлена поддержка репозиториев Veeam B&R.
Теперь мы можем переходить в раздел Applications, где Kasten покажет нам уже все приложения, которые существуют в нашем кластере.

У нас есть 2 пути:
- Создать политику резервного копирования для всех сущностей кластера (кнопка create policy справа, под Cluster-Scoped Resources).
- Создать политики для конкретных приложений.
Политики можно создать и в разделе Policies, но тогда при её создании придётся указывать теги и приложение, которые мы хотим бекапить. Первый вариант просто быстрее и проще. Создадим политику для моего тестового приложения — yelb.
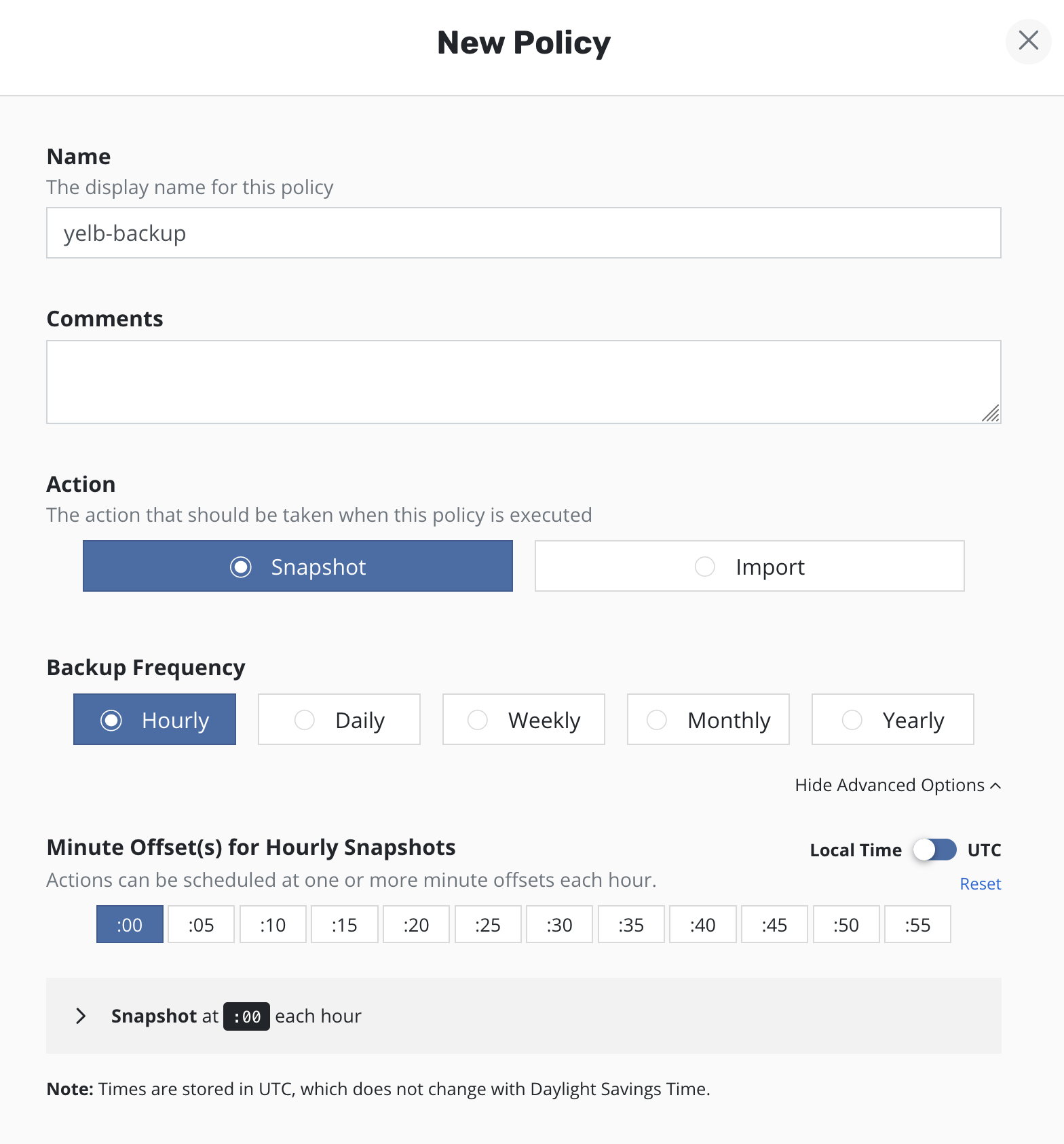
Названия политик и комментарий по вкусу. У нас есть 2 варианта «первого» действия бекапа — сделать снепшот или сразу импортировать его куда-то. Пока остановимся на создании снепшота, выберем как часто мы будем делать бекап и в какое именно время. Minute Offset можно выбрать несколько, соответственно, минимальный RPO у нас получается 5 минут.

Следующим пунктом — время хранения. Крайне гибко настраивается сколько и каких снепшотов мы будем хранить, также можно указать точки, которые будут являться «точкой отсчёта» политики хранения. Тут же мы можем включить «второе» действие и делать копию нашего снепшота во внешнее хранилище, которые мы настраивали до этого. В моём случае это minio. Можно гибко настроить какие именно снепшоты мы будем копировать:
- Every Snapshot
- Every Daily Snapshot
- Every Weekly Snapshot
- Every Monthly Snapshot
- Every Yearly Snapshot
а также настроить отдельную политику хранения снепшотов во внешнем хранилище.
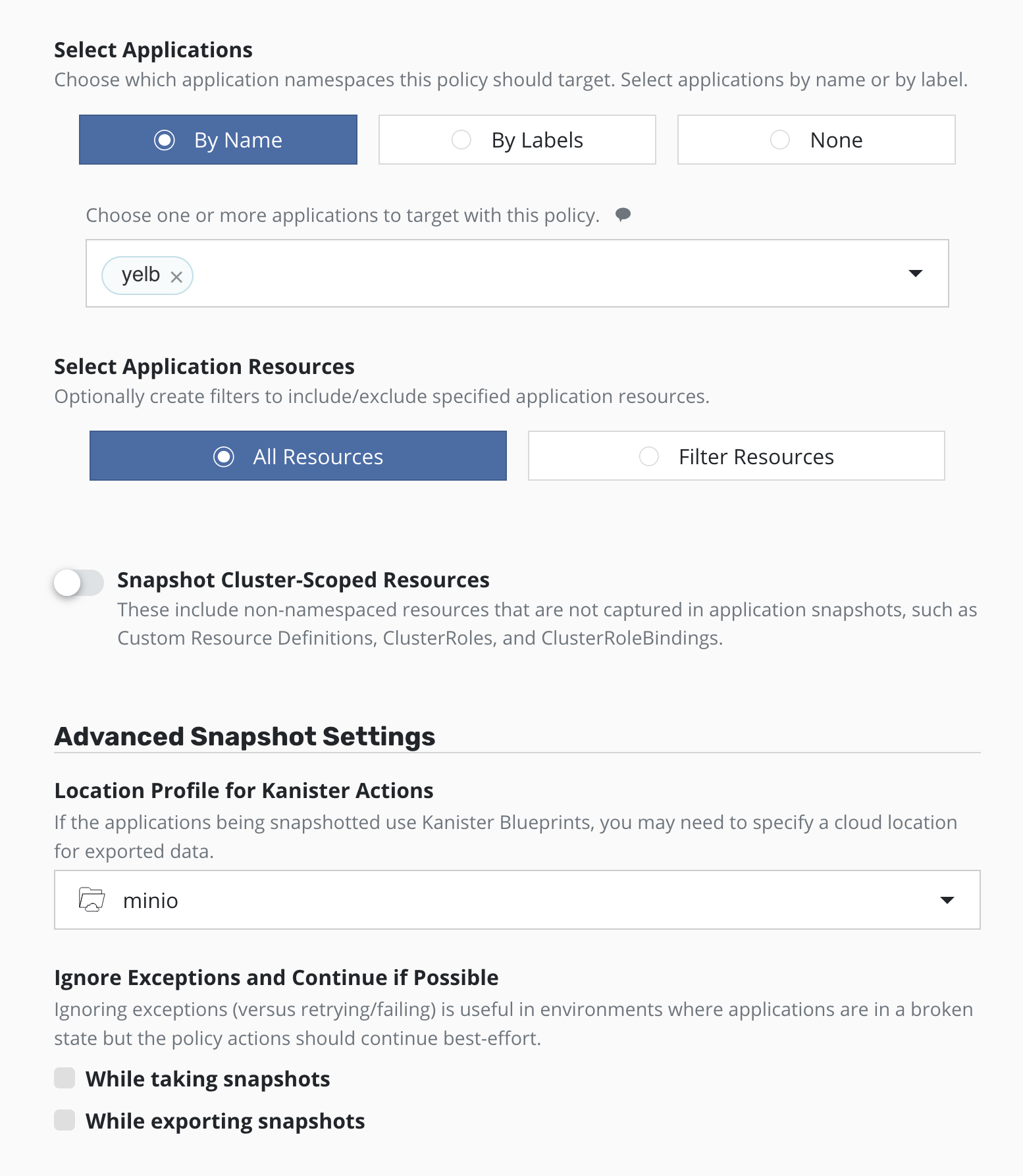
Дальше нам необходимо выбрать наше приложение (или оно уже будет указано, если вы создавали политику через раздел Applications), выбрать какие именно ресурсы вы хотите бекапить, если по какой-то причине требуется не всё, то также указать, где именно будут храниться дампы баз, сделанные при помощи Kanister.
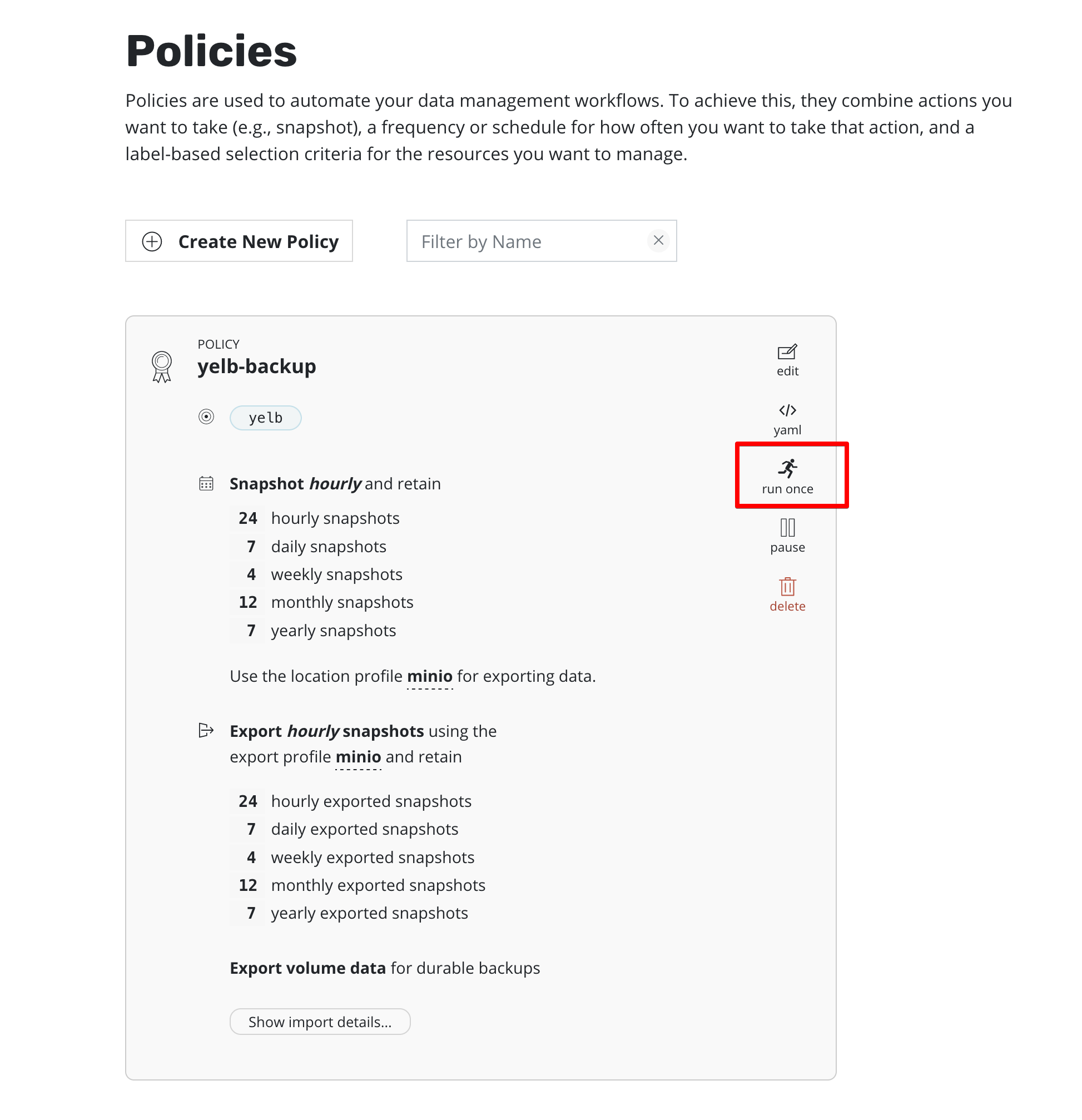
Далее нам остаётся запустить бекап вручную или дождаться его выполнения по расписанию.
За процессом прохождения резервных копий мы можем следить на дашборде
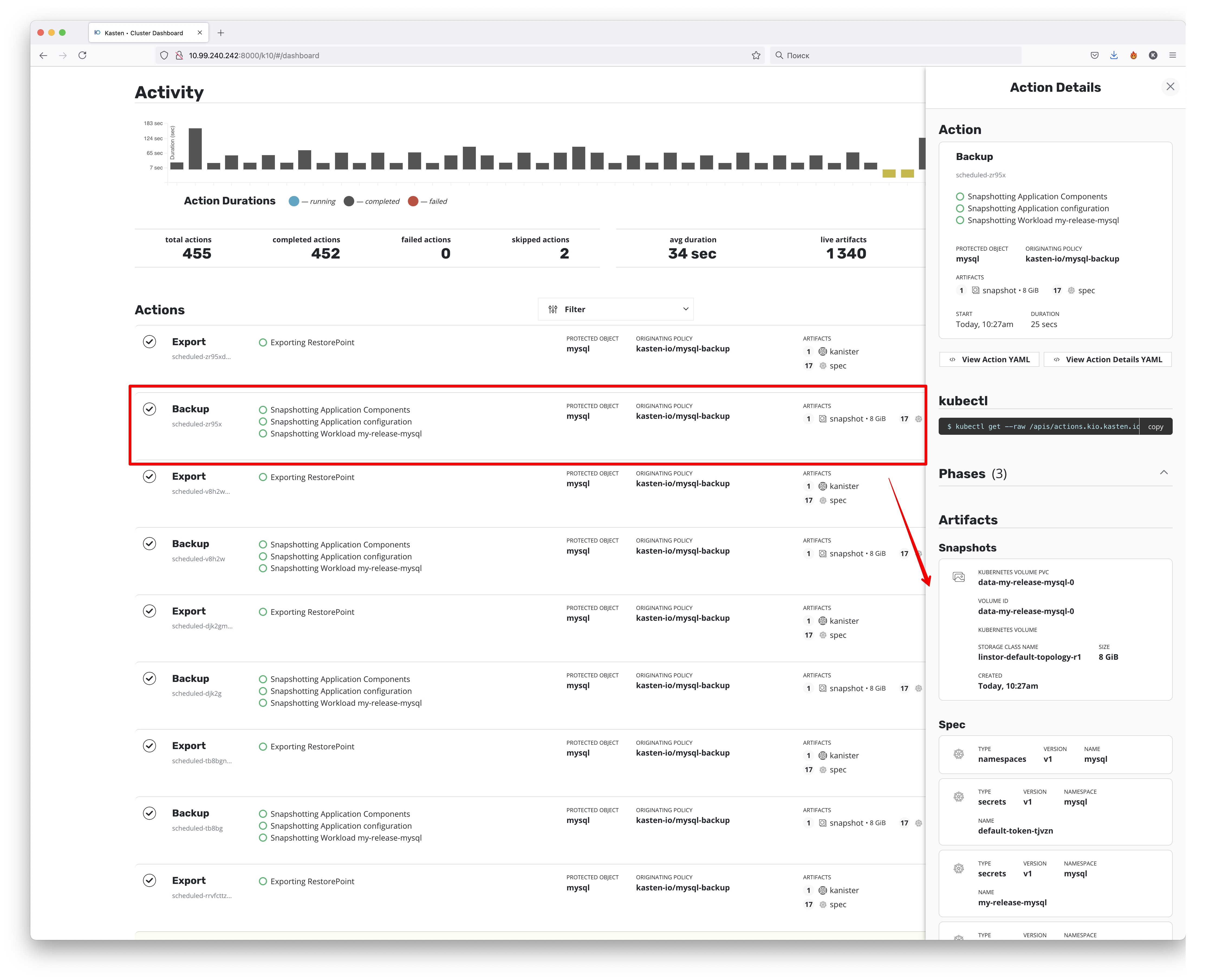
Как мы можем видеть — был сделан снепшот и бекап 17 конфигурационных spec файлов. Если со снепшотом всё понятно — это снепшот PV, который содержит данные, то файлы конфигураций — это конфиги в формате самого Kubernetes, с помощью которых происходит деплой при восстановлении из резервной копии.
Что же касается экспорта данных в дополнительное хранилище, то тут почти тоже самое
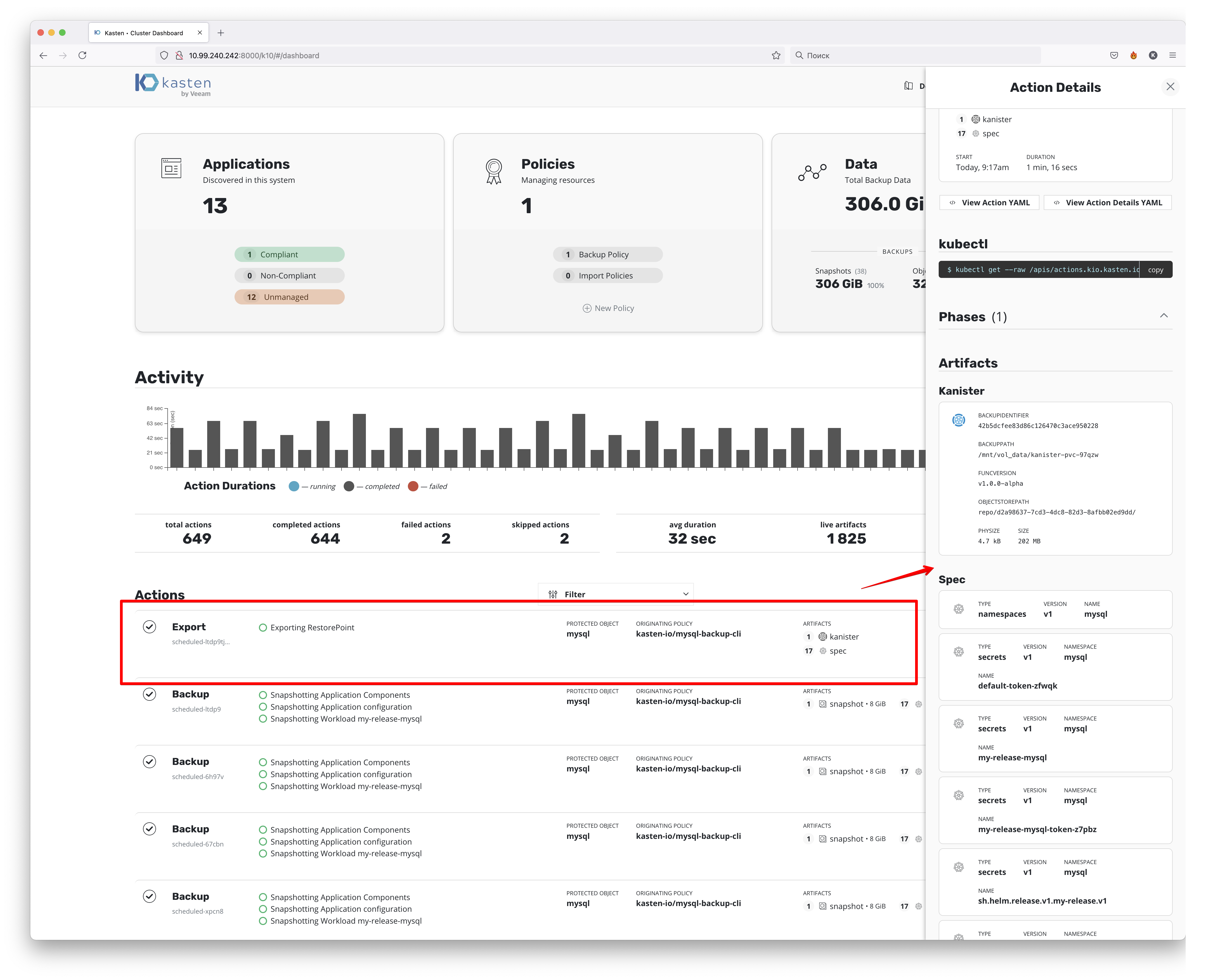
за тем исключением, что в него заливается не сам снепшот, а дамп данных, сделанный при помощи Kanister.
Сам процесс восстановления выглядит как деплой этих конфигов с последующим накатыванием данных из снепшота или из экспортированного дампа данных БД.
Теперь перейдём к самому интересному — процессу восстановления данных. Я решил записать небольшое демо, мне кажется так будет быстрее и проще для понимания.
Теперь вернёмся к управлению Kasten без использования gui. Конечно же он предоставляет API, основанный на Kubernetes Custom Resource Definitions (CRDs), соответственно, это даёт возможно управлять и настраивать Kasten при помощи конфигурационных файлов.
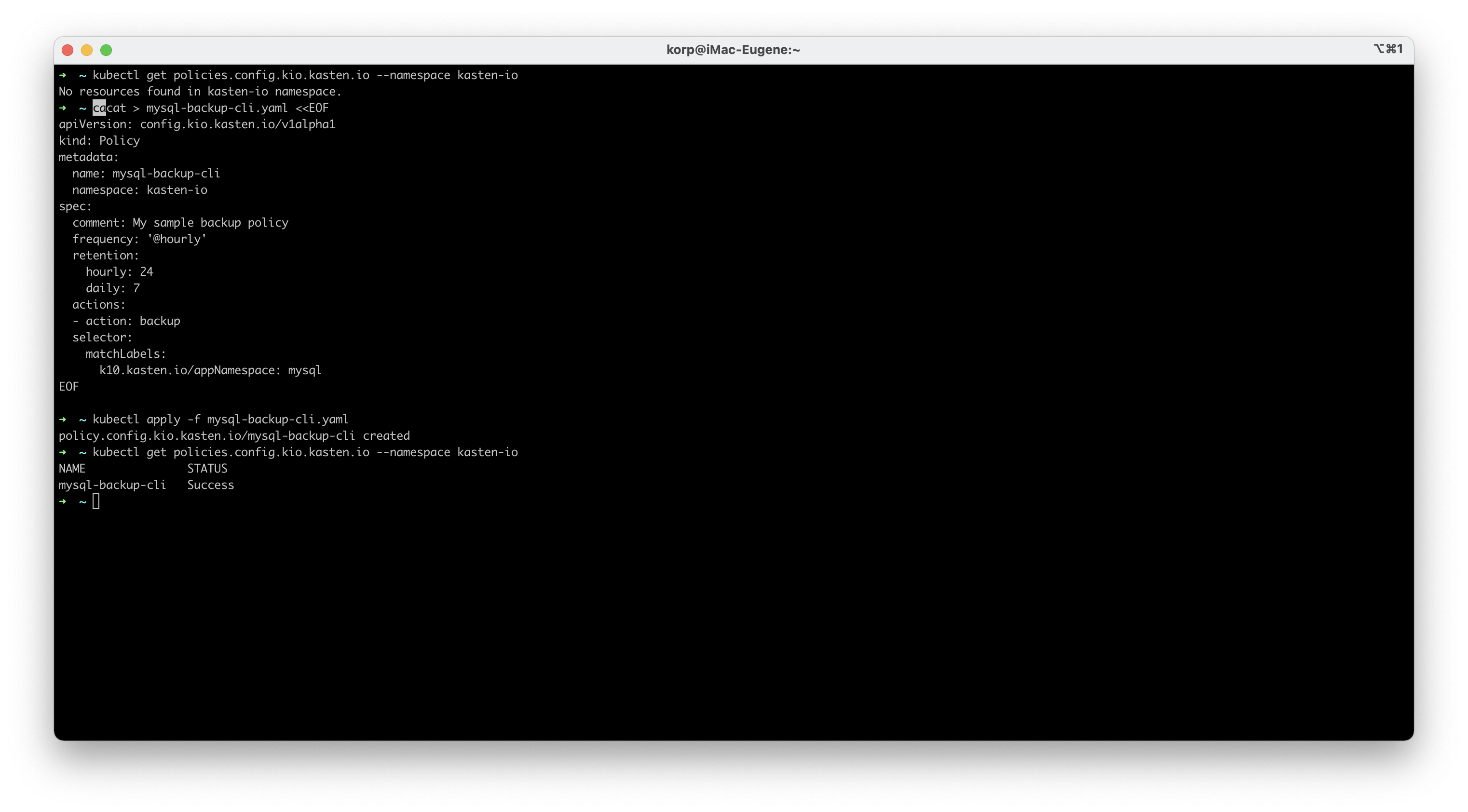
Думаю для первого знакомства этого достаточно. Вы самостоятельно можете быстро попробовать всё это настроить благодаря Hands-On Lab. Либо, как у в VBR, есть бесплатная версия на 10 узлов без ограничения срока действия. При этом редакция Starter не отличается от старших — платных редакций по уровню основного функционала, только по возможностям масштабирования и поддержке. А если у вас остались вопросы, вы хотите больше узнать о Kasten или посмотреть демо — присоединяйтесь уже завтра к VeeamOn Tour Россия, на котором Павел Косарев, технический консультант Veeam, проведёт сессию «Демо: Kasten K10 от Veeam: резервное копирование и послеаварийное восстановление Kubernetes».
А я напоминаю — учебный центр SoftLine предоставит скидку всем участникам VeeamOn Tour на курсы в формате онлайн (с преподавателем, не запись) в размере 40% и скидку на экзамен в размере 10%, при условии прохождения обучения до 30 сентября 2021!
