NetApp для самых маленьких: эффективность хранения

В третьей части моего цикла «NetApp для самых маленьких” я обещал подготовить отдельный материал, посвящённый эффективному хранению данных на массивах под управлением ONTAP и технологиях, этому способствующих. Сегодня мы о них и поговорим.
Thin Provisioning
Если вы изучаете системы хранения данных и уже работали с СХД других вендоров, то я уверен, что вы уже по крайней мере слышали или сталкивались с Thin Provisioning или по простому — “тонкими” лунами. Эта технология позволяет выделить любое количество дискового пространства независимо от того, сколько у вас есть его на самом деле. Чем это отличается от традиционных (когда-то) “толстых” лунов? При выделении толстого луна мы резервируем на дисках объём этого луна только для него независимо от того полностью он заполнен данными или мы используем его только на несколько процентов. При выделении тонких лунов мы отдаём нашим серверам “виртуальный” объём, а данные на дисках занимают ровно тот объём, который они занимают.
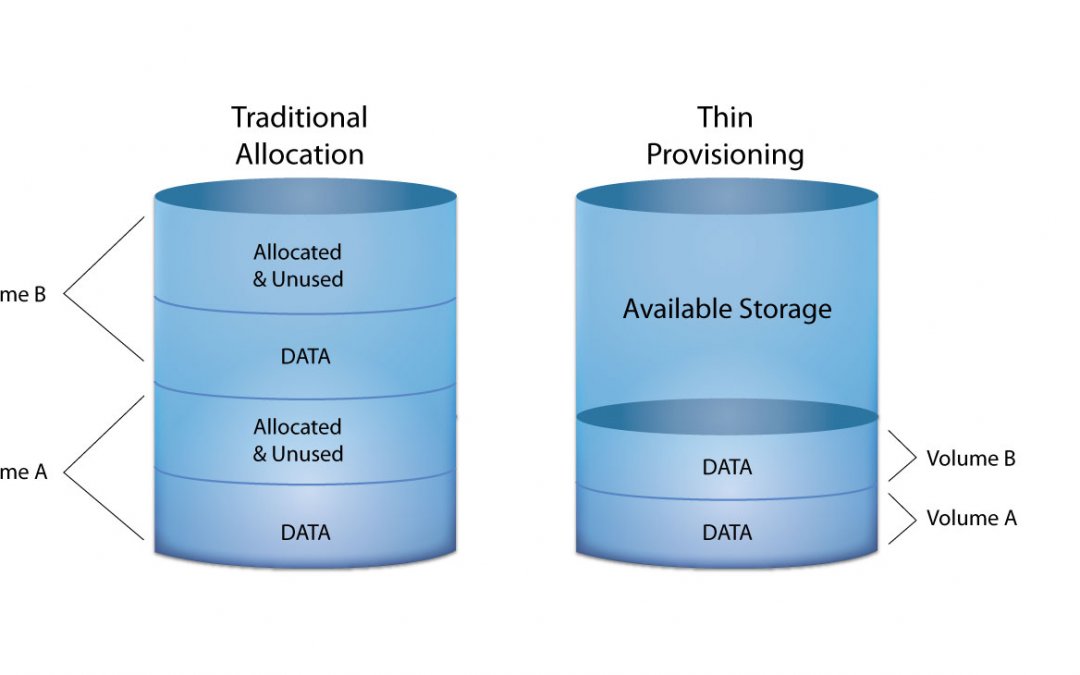
Это позволяет разместить на одной и той же системе хранения больше данных и избежать “неиспользуемого” дискового пространства, которое будет простаивать. Большинство современных систем на сегодняшний день позволяют вам использовать тонкие диски. Это самый простой и эффективный способ экономить выделяемое дисковое пространство, храня на системе только данные, а не резервируя их под будущие нужды. При этом, в отличие от остальных технологий эффективного хранения (которые могут иметь влияние) Thin Provisioning не имеет влияние на производительность. Но это работает в отношении только NetApp, т.к. у некоторых других вендоров производительность толстых дисков выше, чем тонких. Но стоит сразу же оговориться — если вы используете тонкие луны, то вам необходимо очень тщательно следить за физическим заполнением дискового пространства и внимательно планировать размещение новых систем. Если по какой-то причине вы упустите этот момент, то можете получить ситуацию, что ваши системы или пользователи попытаются записать на тонкие луны больше данных, чем физически может поместить на СХД. Это приведёт к переходу СХД в read-only режим (это нормальное поведение любой СХД в данном случае, чтобы гарантировать сохранность данных) и, соответственно, остановке большинства ваших систем. А т.к. система переходит в режим read-only для всех созданных вольюмов (тонких, толстые продолжат работать), то высвободить на ней какое-то количество свободного пространства для восстановления работы систем также окажется довольно трудной задачей. Стоит отметить, что на системах под управлением ONTAP тонкими могут быть как сами луны, так и вольюмы, которые их содержат. И даже если лун у вас толстый, но при этом вольюм тонкий и на нём закончилось свободное пространство, даже толстый лун перейдёт в read-only. Также тонкое выделение поддерживается и для файловых шар.
В свою очередь хосты умеют сообщать массиву о том, что они удалили какие-то данные, что позволяет высвободить пространство и на стороне СХД. Единственное уточнение — на лунах необходимо включить опцию -space-allocation enabled. Есть ещё один очень важный момент, связанный с лунами на системах под управлением ONTAP. Долго думал в какой именно статье об этом написать, но думаю здесь это тоже будет уместно ввиду того, что это связано с высвобождением места на СХД. Дело в том, что после удаления вольюма, который содержал луны, не происходит моментальное высвобождение дискового пространства. Связано это с тем, что после удаления он помещается в очередь на удаление, а удаление происходит через 12 часов. Этот же механизм защищает вольюм (и содержащиеся внутри него луны) от случайного удаления. В ONTAP 9.8 теперь даже в GUI есть функционал его восстановления путём нажатия всего одной кнопки. Раньше же это можно было сделать только из CLI и только в диагностическом режиме. Теперь же это можно выполнить зайдя в раздел Volumes и выбрав More > Show Deleted Volumes.
Deduplication, Compression и другие страшные слова
Прежде чем начать рассказывать об этих технологиях, стоит оговориться, что они постоянно совершенствуются и изменяются в пользу большей эффективности.
Если вы используете устаревшие версии ONTAP (а на момент написания этой статьи актуальной является 9.7, но уже есть 9.8 RC, в которой также произошли изменения в работе некоторых механизмов и говорить мы будем именно в контексте 9.8), то описание ниже может работать не так, как на вашей системе с более ранней версией ONTAP.
Deduplication — это процесс, который устраняет избыточное хранение одинаковых блоков данных. Мы постоянно пишем данные на нашу систему хранения и очень часто наши данные состоят из одинаковых блоков. Хранить их огромное количество копий — нет никакого практического смысла. Дедупликация как раз и позволяет выявлять одинаковые блоки данных и хранить только одну их копию для сокращения использования дискового пространства.

Каждый раз, когда новый блок данных попадает на систему хранения, он разбивается на блоки 4K, которыми оперирует система хранения и высчитывает хэш для этого блока. После этого данный хэш проверяется по таблице хэшей, вычисленных для предыдущих блоков данных, которые уже хранятся на системе с целью найти такой же хэш. Если совпадение найдено, то новый блок и тот, что уже был на нашей СХД, проходят побайтовое сравнение, чтобы быть абсолютно уверенными, что они совпадают. Все эти операции происходят в кэше и если наш «старый» блок данных отсутствовал в кэше, и находился только на накопителях, он предварительно считывается в кэш. Если блоки совпали, то новый блок данных помечается как дубликат и не записывается на накопители, обновляются только метаданные (которые содержат inodes и карты блоков), которые подскажут при чтении, какой «старый» блок данных нужно использовать, когда мы захотим прочитать эти данные. Подробнее про inodes и WAFL предлагаю прочитать в этой статье «Файловая система WAFL — «фундамент» NetApp«. Помимо непосредственной дедупликации блоков данных имеется также механизм zero-block deduplication, его задача проста — исключить нулевые блоки, чтобы они не занимали место и мы хранили только блоки с данными. Zero-block deduplication работает только онлайн и только при включенной дедупликации на вольюме.
Compression — компрессия, попытка уменьшить объём данных на системе хранения. Эффективность сжатия в большей степени зависит от того с какими именно данными вы работаете. Данные сжимаются для «хранения» и разжимаются при их запросе на чтение. Компрессия работает для файлов/блоков (вы уже читали про WAFL и что для неё — «всё файл»?) данных больше 8К. В этом случае он разбивается на части и к этим частям применяется компрессия.
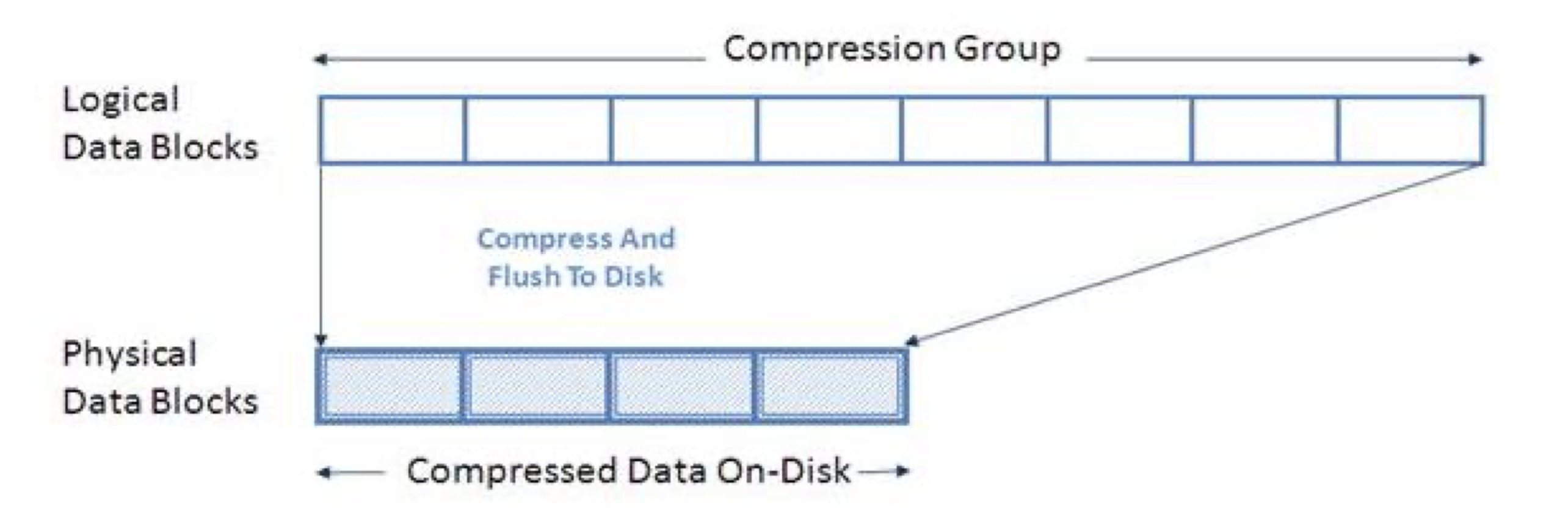
Существует 2 вида компрессии:
- Адаптивная (Adaptive) — размер CG (compression group) 8K. Если система видит, что может сжать эту группу на 50% и более — происходит компрессия и эти данные записываются как один блок данных (если эффективность сжатия менее 50%, то сжатие не происходит). Такой подход даёт не очень высокую степень сжатия и эффективность, но небольшая группа данных может быть быстрее распакована при чтении и, соответственно, быстрее отдана запрашивающему эти данные серверу, чтобы не снижать производительность. Лучше всего подходит для рандомных нагрузок.
- Второстепенная (Secondary) — размер CG увеличивается до 32К, что увеличивает эффективность сжатия. В остальном же логика та же, что и для адаптивного сжатия, только здесь порогом сжатия является уже не 50, а 25%.
Мы можем использовать один из двух вариантов компрессии. Если мы хотим его сменить, то предварительно необходимо отключить компрессию, чтобы разжать уже сжатые данные, а затем включить уже с новым алгоритмом работы и пережатием данных. Для Inline и post процессинга используется один и тот же выбранный тип компрессии. Сжатие работает как для SSD, так и HDD, поддерживается в том числе и Flash Pool.
Compaction — как я уже говорил выше, системы хранения под управлением ONTAP работают с блоком 4K. Т.е. независимо от того, каким блоком вы пишете на систему, они разбиваются на блоки 4K, которые уже записываются на накопители. Но что происходит в случае, если ваш блок не кратен 4K, он меньше, либо его размер уменьшился после компрессии? Мы бы в блок 4K на СХД положили наш блок данных меньшего размера и записали. Представим, что нам нужно записать 4 блока размером 1K — на СХД это заняло бы 4 блока по 4K, т.е. 16K. Не эффективно. Как понятно из названия технологии, она создана для того, чтобы уплотнить блоки данных, попадающие на СХД перед записью их на накопители. Пока данные находятся в кэше контроллера, система пытается собрать эти маленькие блоки данных в один 4K блок и уже после этого записать их.
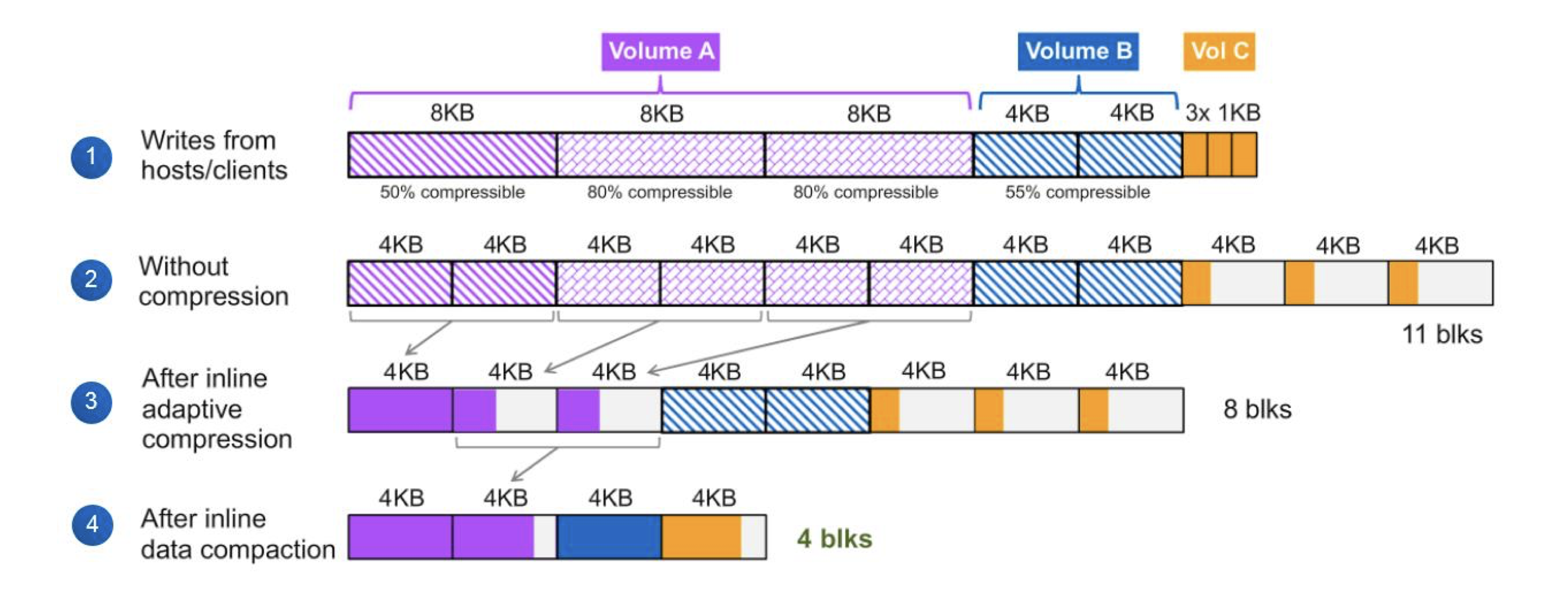
При этом данный процесс «отъедает» всего 1-2% от производительности CPU контроллера и никак не влияет на производительность системы. Работает только inline, на уровне вольюма.
Inline и Postprocess
Часть технологий эффективности работает до записи данных на накопители, другая же часть может работать как до записи, так и после. Inline — это те операции, которые производятся до записи на накопители, пока данные находятся в кэше контроллеров, а postprocess, соответственно, операции, которые проводятся уже когда данные находятся на накопителях. В частности — компрессия и дедупликация могут быть как inline, так и postprocess. Inline операции, помимо того, что позволяют экономить дисковое пространство, так ещё позволяют уменьшить нагрузку на накопители — для классических HDD это значит, что мы снимем часть нагрузки на запись данных, а для SSD это позволит уменьшить количество записей на накопитель, что положительно скажется на их сроке жизни. Postprocess компрессия и дедупликация могут быть запущены вручную, по расписанию или при преодолении порога новых записанных данных (по-умолчанию 20%). При этом для дедупликации и и компрессии используется единое расписание.
Что и где работает:
AFF
- Inline дедупликация, компрессия и компашн включены по-умолчанию
- Тип компрессии по-умолчанию — Adaptive с блоком 8K
- Postprocess компрессия не поддерживается (но если вы выключите inline компресиию на вольюме, то для её включения придётся сначала так же включить postprocess, но он не будет работать)
- Дедупликация в пределах аггрегата (сначала выполняется на уровне вольюмов, затем на уровне аггрегата)
FAS
- Inline дедупликация, компрессия и компашн выключены по-умолчанию (исключение составляет только FlashPool). Связано это с некоторыми отличиями ONTAP для FAS и AFF систем и считается, что для FAS систем inline процессинг может негативно влиять на производительность, хотя если мы к примеру возьмём AFF A700 и FAS9000 — физически это одна и та же железка с одинаковыми характеристиками. И тем не менее, никто не запрещает вам включить inline процессинг на FAS системах самостоятельно, только в этом случае очень рекомендую крайне внимательно следить за утилизацией CPU на контроллерах и очень хорошо понимать зачем вы это делаете и стоит ли экономия этого.
- Тип компрессии по-умолчанию — Secondary с блоком 32K
- Postprocess дедупликация и компрессия поддерживаются
- Дедупликация в пределах вольюма
В каком порядке работают все эти технологии.
До версии 9.8:
- zero-block deduplication
- compression
- deduplication
- сompaction
В 9.8 порядок поменялся:
- zero-block deduplication
- deduplication
- compression
- сompaction

Связано это с появлением нового механизма компрессии — TSSE (Temperature sensitive storage efficiency), который работает теперь не на уровне файла WAFL, а на более низком уровне контейнера (ближе к физике, к аггрегату, с логической точки зрения), что позволяет пережимать холодные блоки данных, собирая их в большие CG. ONTAP давно научился определять холодные и горячие данные — на основе этого механизма был реализован, скажем так, тиринг в облако (в S3 хранилище, в терминологии NetApp это FabricPool). Теперь при использовании TSSE (или auto-adaptive, так оно будет называться в интерфейсе ONTAP) «горячие» данные прилетающие на нашу СХД будут по прежнему inline сжиматься размером группы 8K, а холодные данные (порог будет настраиваться, по-умолчанию будет 14 дней без обращения к данным вообще) в пост процессе будут разжиматься и сжиматься группой в 32K. Единственное, чего на мой взгляд не хватает этому механизму, это возможности указать некое «окно РК». Даже если к данным нет обращения с продуктивной системы, вполне вероятно, что эти данные могут быть прочитаны при прохождении очередного бекапа. ONTAP увидит это обращение к данным и двухнедельный таймер запустится с нуля. А если бы мы могли по шедулеру указать время, когда ONTAP не должен реагировать на обращение к данным и тогда таймер не будет сбрасываться и данные пережмутся через 2 недели. Конечно стоит упомянуть и минус такого подхода — данные сжатые большей группой будут медленнее читаться, но и не всем нужен сверхбыстрый бекап.
Компания NetApp (и их тесты) считают, что TSSE более эффективен.
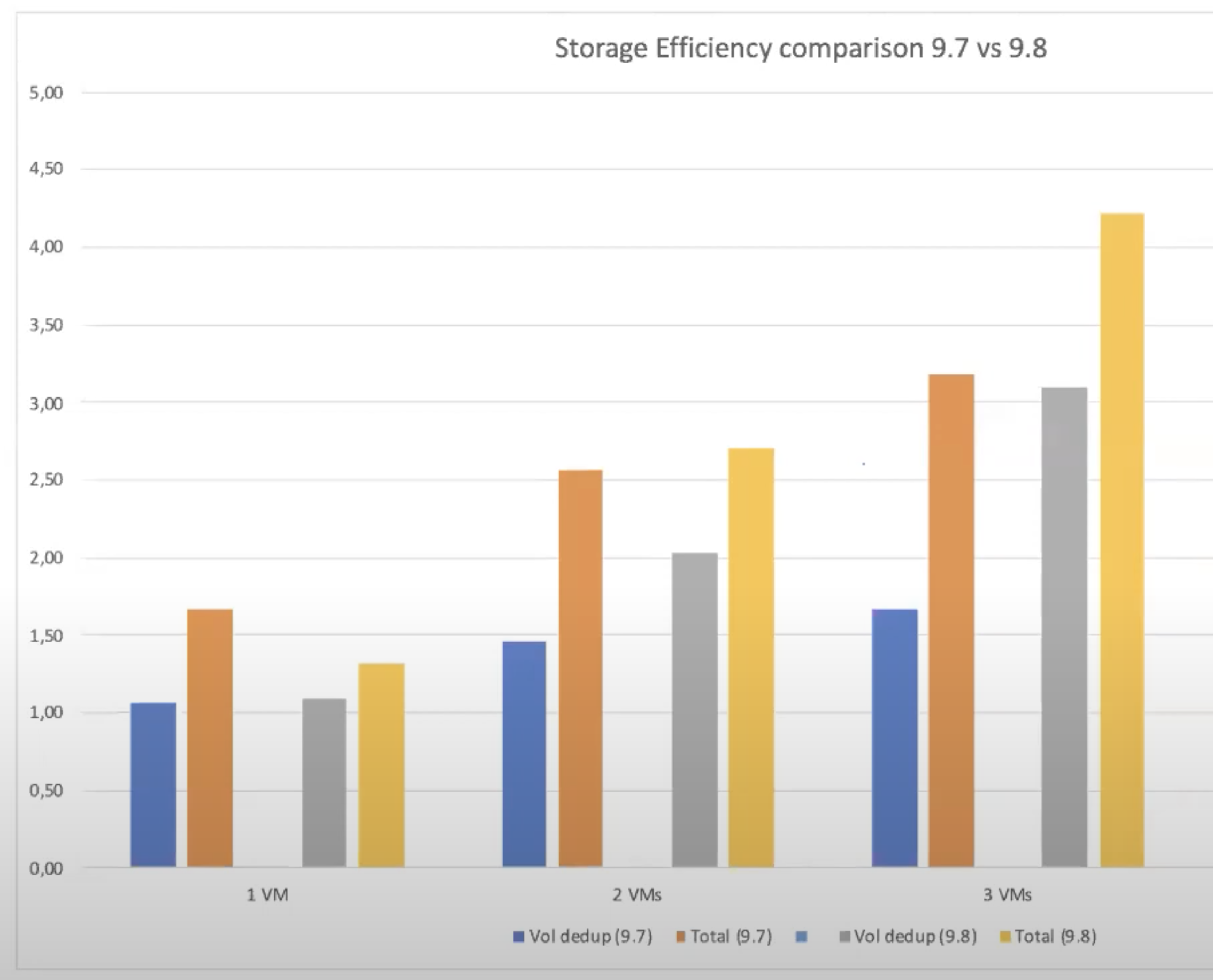
Рекомендации по работе с дедупликацией и компрессией:
- AFF — всё включайте по-умолчанию
- FAS — лучше не использовать inline технологии, если сильно хочется, то лучше поэтапно и наблюдая как это влияет на производительность
Есть подробный и интересный документ TR-4476 NetApp Data Compression, Deduplication, and Data Compaction, в котором так же даны рекомендации, но дело в том, что документ этот уже довольно старый и рекомендации в нём больше имеют отношение к FAS системам, которые были на тот момент в большем количестве, нежели AFF. Поэтому к данному документу стоит относиться крайне осторожно. Но учитывая, что в 9.8 завели много нового по части дедупликации и компрессии , вероятнее всего этот документ в скором времени освежат и в нём появятся актуальные рекомендации. Номер TR при этом не изменится, поэтому ссылка останется та же.
Теперь же, когда мы немного разобрались с тем что и как работает и, вероятно, уже даже включили какой-то функционал, нам нужно понять — что мы от этого всего получили?
Конечно самым первым вариантом мы можем эффективность в GUI.
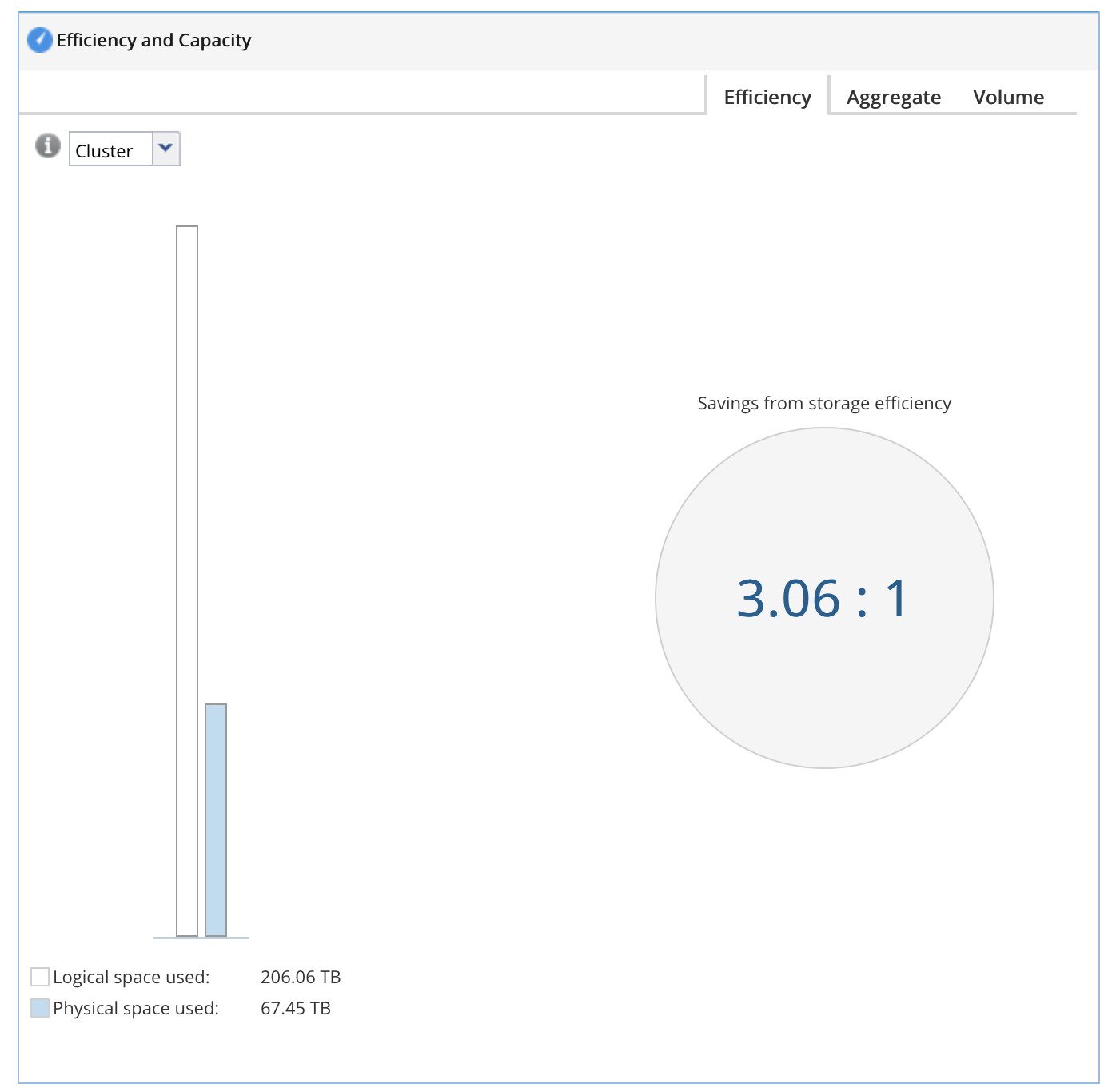
Плох этот вариант тем, что показывает обобщённую картину по всей системе. А как мы понимает — разные данные на разных томах могут сжиматься совершенно по-разному, а где-то у нас механизмы эффективности вообще могут быть отключены ввиду отсутствия в них практического смысла. Поэтому на много интереснее и понятнее смотреть более конкретно. Для AFF системы мы можем посмотреть на уровне аггрегата
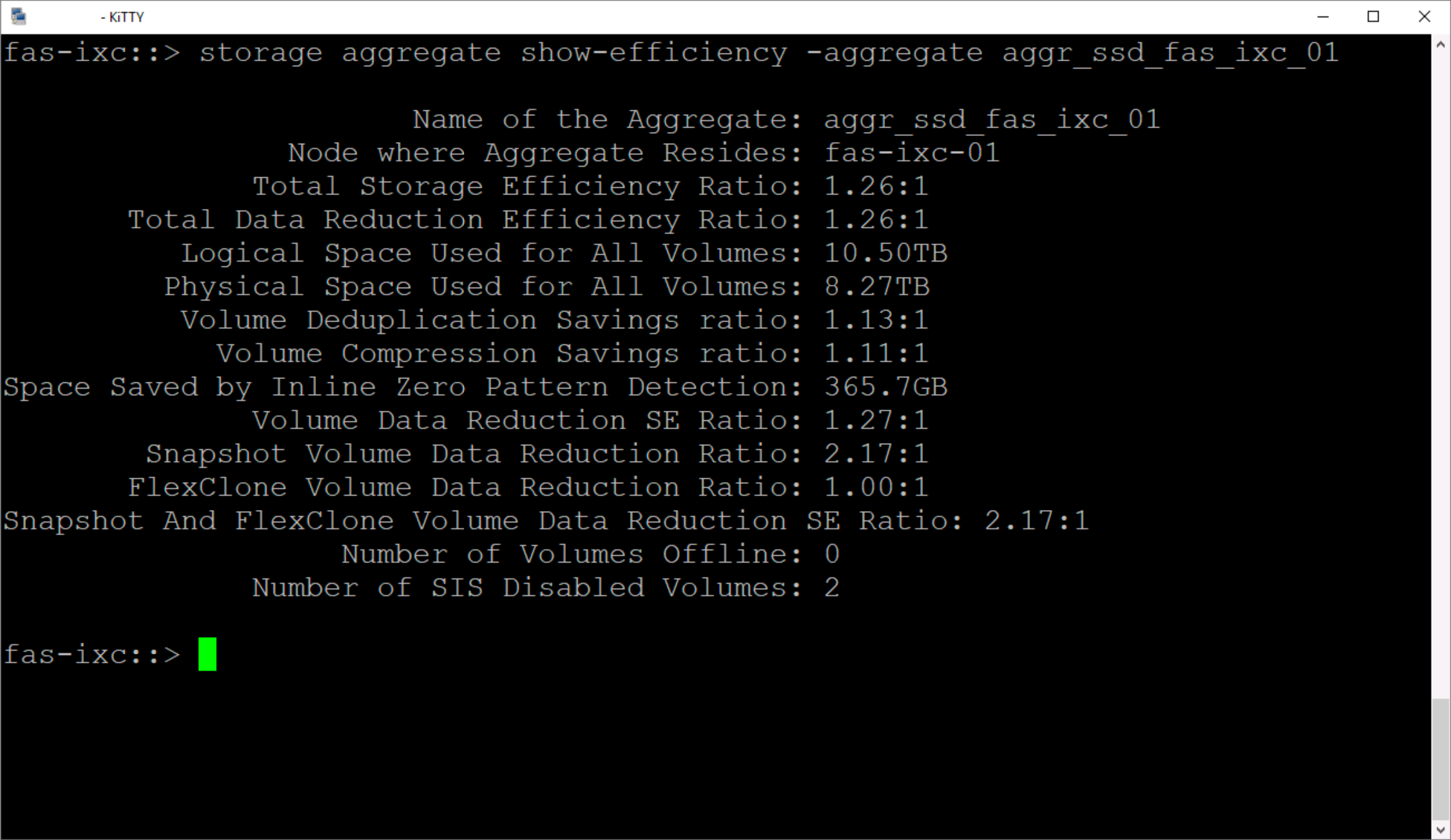
Но этот вариант в чём-то схож с общей оценкой эффективности на уровне всей СХД, поэтому более детально нужно смотреть по вольюмам

Здесь мы уже понимаем на каком вольюме какие данные у нас лежат, что позволяет сравнить эффективность между различными продуктивными системами. Провести анализ того, что размещено на данных лунах и, возможно, для большей эффективности произвести миграцию между лунами. В целом, с этими данными можно уже работать, чтобы повысить коэффициент эффективности системы.