Что такое NetApp MetroCluster прекрасно и подробно рассказал Дмитрий Березенко, в своей статье NetApp MetroCluster (MCC). Но за всё это время, мне не попадалось в рунете практических статей по этой теме. Я решил исправить этот недостаток, тем более что как раз сейчас мы строим MetroCluster на базе NetApp FAS для одного из наших клиентов. В целом, всё это описано в документации, и я постараюсь лишь дополнить эту информацию собственным мнением, сделать понимание теории более понятным и рассказать некоторые неочевидные моменты, ну и собрать ссылки на всю необходимую документацию.
Вводная
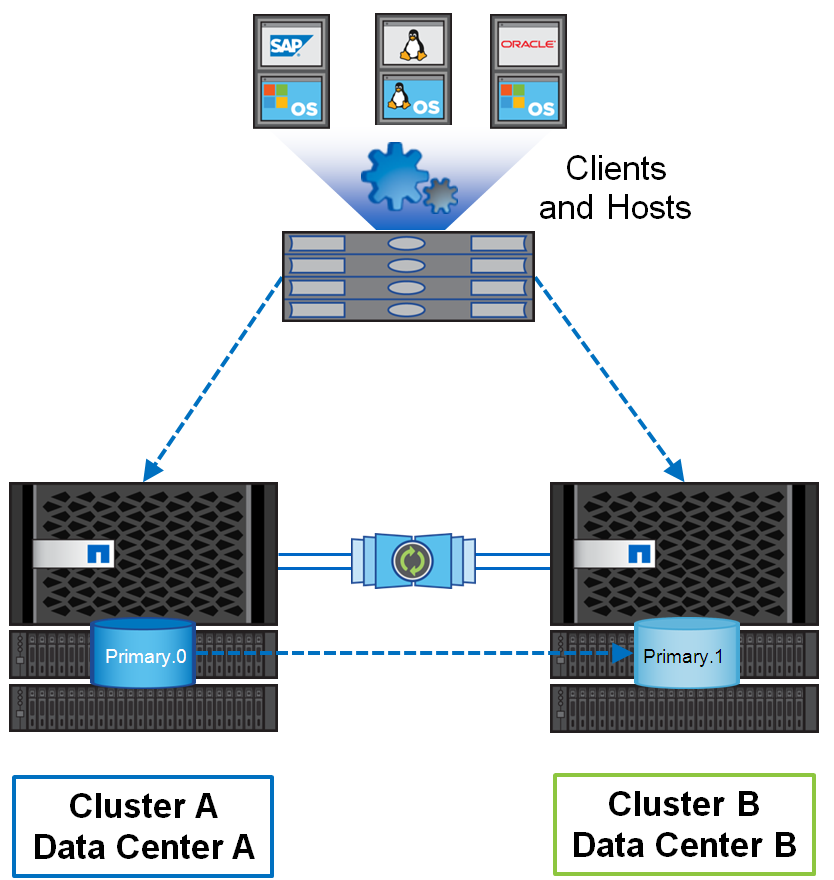
Мы выбрали вариант Fabric-attached MetroCluster в 4-х нодовой конфигурации.
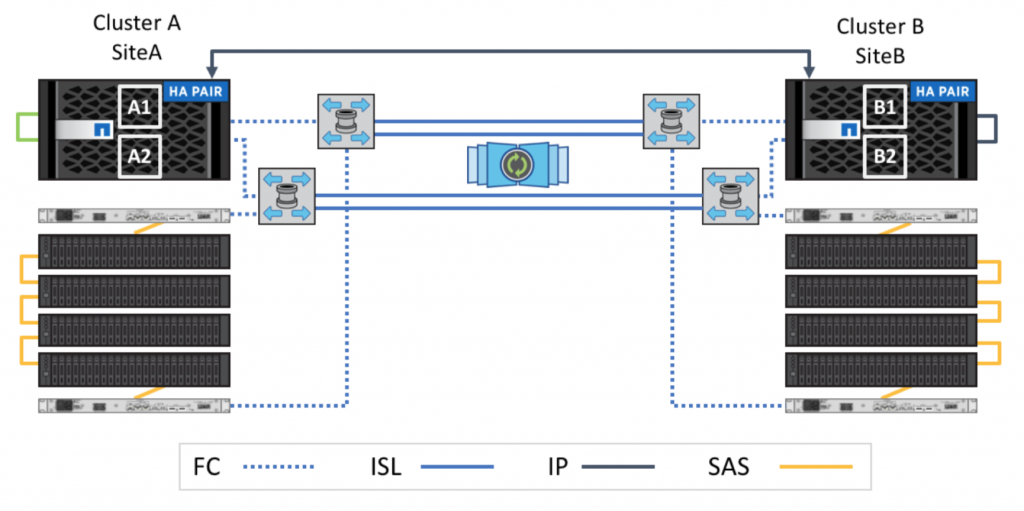
В качестве контроллеров использовались NetApp FAS 8200, которые были установлены на каждой из площадок, а также по 8 полок (4 с SAS и 4 с SSD накопителями) на каждой из площадок. Соединение кластеров было выбрано по FC. Это даёт некоторые преимущества по сравнению с IP. Подробно они описаны в документе TR-4705 MetroCluster Solution Architecture and Design в разделе «2.2 Comparing MetroCluster FC and MetroCluster IP». Нас интересовало в данном случае 2 вещи:
- Возможность расширения до 8 нод.
- Отсутствие прямого подключения полок к контроллерам, что даёт возможность контроллерам на второй площадке видеть полки, даже в случае выхода из строя контроллеров, которым они принадлежат.
Из минусов — отсутствие поддержки Advanced Disk Partitioning (ADP).
Подключение

Подключение делится на несколько этапов на каждой из площадок:
- Интеркластерное соединение. Описано в FAS8200 Systems Installation and Setup Instructions.
- Подключение полок между собой и к SAS-FC бриджам. Описано в Cabling a FibreBridge 7600N or 7500N bridge with disk shelves using IOM12 modules.
- Подключение SAS-FC бриджей к FC коммутаторам. Описано в Fabric-attached MetroCluster Installation and Configuration Guide в секции Port assignments for FC switches when using ONTAP 9.1 and later.
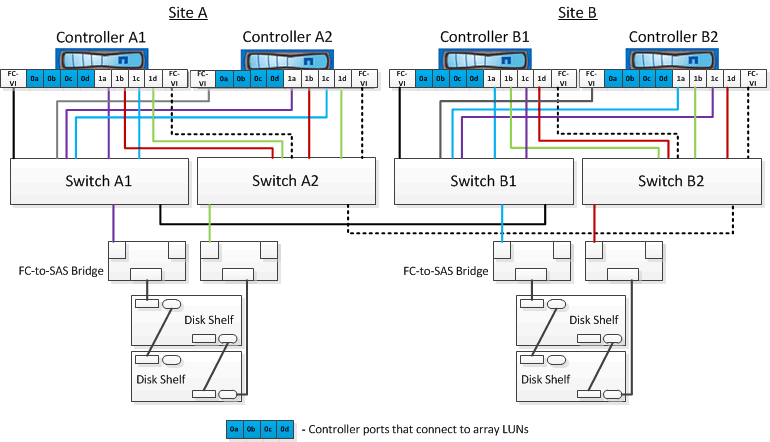
- Подключение контроллеров к FC коммутаторам. Описано в Fabric-attached MetroCluster Installation and Configuration Guide в секции Port assignments for FC switches when using ONTAP 9.1 and later. Здесь следует обратить внимание, что в зависимости от вашей спеки, могут отличаться FC-VI порты:
AFF A300 and FAS8200 storage systems can be ordered with one of two options for FC-VI connectivity:
Onboard ports 0e and 0f configured in FC-VI mode.
Ports 1a and 1b on an FC-VI card in slot 1.
Так же там есть ещё несколько нюансов, в зависимости от того, какие контроллеры вы используете. - Менеджмент. Думаю, тут проблем нет.
Настройка оборудования
Первым делом нужно правильно определить FC-IV порты на контроллерах, т.к. в дальнейшем мы будем использовать конфигурацию коммутаторов, предоставленную вендором, и мы уже подключили наши контроллеры согласно рекомендациям к FC коммутаторам.
FC коммутаторы приезжают без предварительных настроек, поэтому подключаемся к ним консольным кабелем, настраиваем менеджмент, как я описывал в статье Brocade SAN Часть 2: Инсталляция и конфигурирование, после чего можно переходить к настройке. Нам не нужно ломать голову с зонированием, компания NetApp уже о нас позаботилась и на саппорт сайте в разделе Download есть раздел MetroCluster RCFs, где можно
взять готовые конфиги для разных моделей коммутаторов и вместе с тем, там же находится инструкцию по обязательным параметрам, которые вы должны сконфигурировать для корректной работы и как залить конфиги на сами коммутаторы.
Следующим шагом станет настройка FC-SAS бриджей. Тут мне не встретилось никаких неожиданностей, всё делается просто по инструкции.
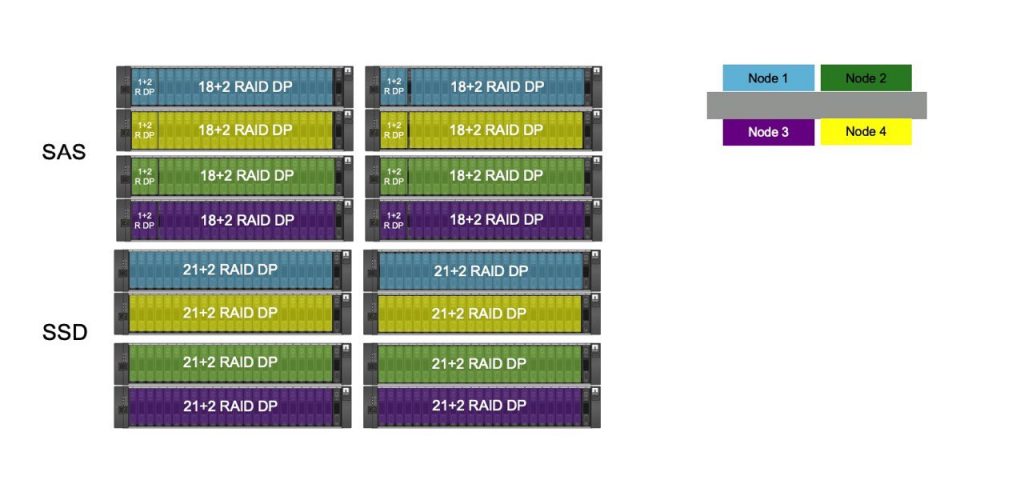
Теперь нужно разобраться с дисками, прежде чем переходить к настройке ONTAP. У меня возникли сложности при назначении дисков конкретным контроллерам. Описание в документации было довольно сжатым, а пример наоборот — сбивал с толку.
disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0
Лично у меня было 2 вопроса: через какой именно коммутатор наших двух фабрик необходимо производить назначение дисков и почему в примере указаны порты 1-4, которые по той же документации используются для соединения двух кластеров, а для подключения SAS-бриджей к коммутаторам порты с 8 и выше.
Методом проб мы поняли, что с портами это скорее всего неточность в документации, а имена коммутаторов — зависят от того, как контроллер увидел диски в данный момент, т.е. может быть ситуация когда мы видим диски только через один из двух контроллеров, а может быть и через два (кстати, указание диапазона портов у нас не сработало, указывали порты по одному), соответственно делая assign мы должны убедиться, что все 12/24 диска были привязаны в нужному контроллеру.
Т.к. в нашем случае мы используем FC вариант MetroCluster, контроллеры обеих площадок имеют независимый доступ к полкам на обеих площадках. Ввиду этого, мы должны привязывать локальную и зеркальную полку к каждому из контроллеров.
Далее нам остаётся запустить обе системы в обычном режиме и настроить кластера. Изначально на каждой из площадок у нас будет отдельный кластер, на начальном этапе конфигурирования система не знает, что мы собираемся делать из неё метрокластер, поэтому конфигурируем двухконтроллерный кластер.
А после уже настраиваем порты, которые будут использоваться для интеркластерного соединения, в зависимости от конфигурации наших контроллеров — выделенные порты или будем шарить их с дата портами. Оба варианта описаны в документации. После чего уже выполняем cluster peer и «дружим» два наших кластера между собой.
Главной особенностью любого метрокластера является то, что данные от хостов пишутся у нас одновременно на две площадки. Для этого у нас все агрегаты должны быть зеркалированы. В том числе и root агрегаты. Соответственно, мы должны сделать storage aggregate mirror для root агрегатов и создать data агрегаты так же в состоянии mirror — storage aggregate create … -mirror true. Стоит отметить, что вы можете использоваться и агрегаты без зеркалирования. В этом случае они будут работать как обычные агрегаты на каждой из площадок. Благодаря этому, вы можете довольно гранулярно определять, какие данные требуют зеркалирования, а какие нет.
Если всё было сконфигурировано верно, то достаточно запустить команду metrocluster configure для инициализации метрокластера. Нам потребовалось некоторое количество времени, чтобы устранить различные ошибки, которые были найдены при инициализации метрокластера и после устранения оных, всё поднялось с первого раза.
Работа метрокластера проверяется при помощи команды metrocluster check run и последующего вызова metrocluster check show.
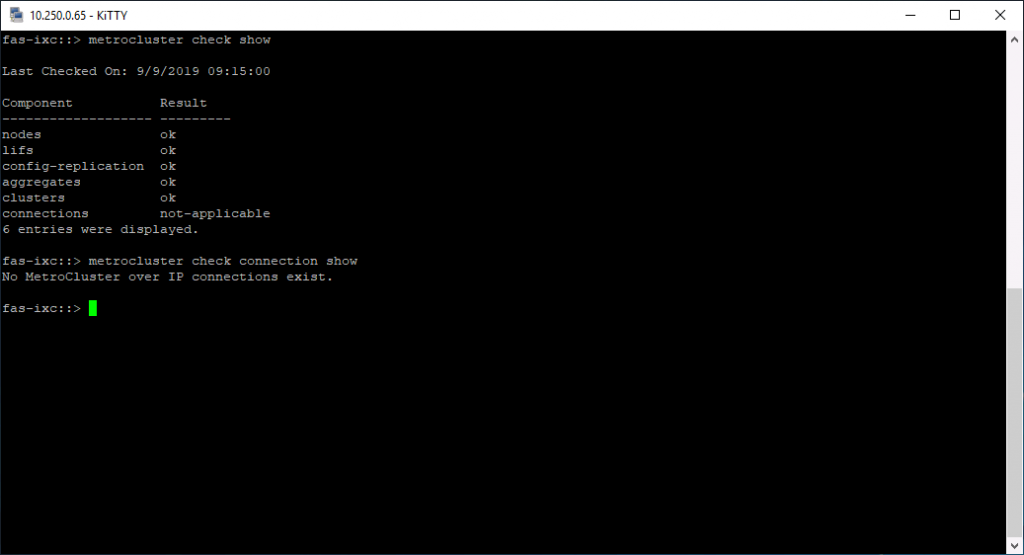
Не стоит сразу пугаться, если есть какие-то ошибки, вполне возможно, что они просто не распространяются на вашу систему (как в моём случае на скриншоте выше). Необходимо детально посмотреть на возможные ошибки по каждому из разделов:
metrocluster check aggregate show
metrocluster check cluster show
metrocluster check config-replication show
metrocluster check lif show
metrocluster check node show
Вторым инструментом, который поможем вам понять, что всё сделано корректно — ConfigAdvisor. Он тоже не идеален и может показать ошибки, которые не будут относиться к вашей системе ввиду того, что они к ней просто не применимы.
Теперь у нас остаётся небольшой, но крайне важный компонент, для корректной работы метрокластера — Tiebreaker. Это ПО от компании NetApp, которое разворачивается на Linux. Скачивается она также с support сайта NetApp. Развёртывание не составляет труда, а вся конфигурация сводится к тому, что бы добавить наши кластеры в мониторинг Tiebreaker’а, подробнее это описано в Tiebreaker Software 1.21 Installation and Configuration Guide. Его поведение никак не конфигурируется. Организация каналов доступа до контроллеров должна быть выполнена вами самостоятельно. Над местом размещения Tiebreaker’а и организации каналов доступа, конечно, стоит подумать и позаботится заранее, т.к. именно он будет отвечать за корректное переключение площадок и разрешении ситуации со split brain.
После того, как все службы запущены, конфигурации не выдают ошибок и на первый взгляд кажется, что всё работает корректно, остаётся только нарезать луны, создать на них тестовую нагрузку и начать проводить испытания отказоустойчивости.
Но перед проведением тестов, неплохо бы ещё настроить и мониторинг. Помимо вполне очевидного для систем NetApp развёртывания OnCommand Unified Manager, нужно добавить FC коммутаторы и SAS-бриджи на мониторинг на самих массивах.
storage switch add -address ipaddress для каждого из FC коммутаторов
storage bridge add -address 0.0.0.0 -managed-by in-band -name bridge-name для каждого из SAS-бриджей
Достаточно добавить на одной из площадок, т.к. конфигурации контроллеров у нас синхронизируются, они будут видны на обеих площадках.
Работа механизмов отказоустойчивости определяется при помощи стресс-тестирования. Поочерёдно отключаются следующие компоненты SAN:
- Коммутатор в одной из фабрик
- Одна из фабрик
- Один из контроллеров СХД
- Второй контроллер СХД после возвращения на место первого и отработки процесса failback на СХД
- Отключение питания СХД, для тестирования работы switchover на уровне Metrocluster.
- Отключение питания дисковых полок, для тестирования работы switchover на уровне Metrocluster.
- Отключение всей стойки СХД, дисковых полок, коммутаторов, sas-бриджей
Этот тест стоит повторить для систем на обеих площадках поочерёдно, проверяя при этом работоспособность систему виртуализации и VM, которые должны в этот момент создавать тестовую нагрузку.
Ещё один тест, который стоит провести, связан с доступностью СХД для Tiebreaker’а и поведение СХД при недоступности самого Tiebreaker’а, а также поведение системы при падении одного из ЦОДов в момент перезагрузки Tiebreaker’а.
В целом я могу сказать, что тестам необходимо уделить больше времени, чем это кажется на первый взгляд, чтобы убедиться в доступности и корректной работе всего комплекса, только это позволит вам спать спокойно.