HPE StoreOnce Часть 5: Дедупликация
Инлайн (до записи на диск) дедупликация и компрессия являются сильной стороной данной системы. Именно эти технологии делают это решение прекрасным для хранения большого качества резервных копий с большой глубиной. И несмотря на то, что никаких инноваций в данных механизмах эта система не представляет, именно на задачах хранения резервных копий большого количества данных, достигаются высокие показатели эффективности хранения.
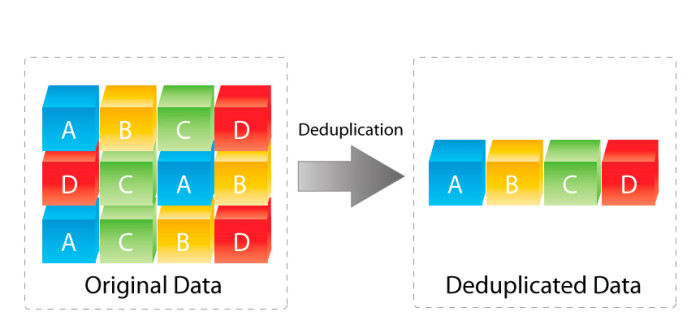
Что вообще представляет из себя дедупликация? Это механизм, который позволяет исключить повторяющиеся блоки данных. В результате этого процесса мы храним на дисковой системе только уникальный набор блоков данных и метаданные. При чём дедупликация на уровне блоков более эффективна, нежели на уровне файлов. При поступлении данных на массив, он проверяет блоки на наличие таких же блоков данных. Если блок уникальный — он записывается на массив. Если же, такой блок уже есть на массиве, сами данные отбрасываются и вместо него записывается ссылка на необходимый блок данных. Во-первых, этот процесс быстрее, чем запись блока данных, во-вторых он позволяет экономить место на дисках. Конечно эффективность этого механизма зависит от типа передаваемых данных, но в контексте сегодняшнего материала, мы говорим о резервном копировании и здесь его эффективность, за счёт записи повторяющихся наборов данных, довольна высока. Так же уровень дедупликации зависит и от того — как долго мы храним резервные копии, т.е. как много данных у нас уже записано на массив.
Вторым же методом повышения эффективности хранения, является компрессия. На StoreOnce, каждый блок данных, после прохождения дедупликации и перед записью на диск проходит процедуру компресси по алгоритму LZ (Lemped-Ziv). Это позволяет уменьшить блок данных в 1.5-2 раза.
Важное замечание — хотя дедупликация на StoreOnce работает для всех типов шар (Catalyst, NAS, VTL), но данные между ними не дедуплицируются. По этой причине лучше класть “похожие” данные только на NAS или только на VTL для получения лучшего результата. Тем более, что для разных типов данных можно получить совершенно разные коэффициенты дедупликации. Какие-то типы данных (виртуальные машины) жмутся и дедуплицируются лучше, какие-то (БД) хуже.