Infortrend GS: страх, ненависть и безысходность
В поисках недорогого и универсальном хранилища, с поддержкой большого количества файловых протоколов и блочного доступа, мы по совету нашего дистрибьютора приобрели в конце 2017 года массив Infortrend GS 3060RL. Как выяснилось позже наш дистриб к тому моменту уже потерял статус официального дистрибьютора Infortrend и в итоге массив к нам приехал только в начале февраля. Этот крайне недорогой массив позволяет использовать как файловый, так и блочный доступ к данным, отсутствует вендор-лок на диски и при этом может работать как по iSCSI, так и по FC протоколам имея универсальные порты. На тот момент для нас это выглядело идеальным вариантом для организации хранения резервных копий.
GS — это унифицированное хранилище, разработанное как для производительного хранения данных на вашей площадке, так и более медленного, но неограниченного хранения данных в облаке провайдера. Это в некоторой степени универсальный перочинный нож среди СХД в данной ценовой категории.
Конфигурация:
- Модель: GS 3060RL, модель с двумя контроллерами
- Процессор: Intel Broadwell-DE (Pentium) 2 Core / 4 Core
- Оперативная память: 8 GB (на каждый контроллер)
- Порты:
- 8 Интегрированных портов 1Gb/s iSCSI
- До 16 FC портов
- До 8 InfiniBand портов
- Блочный доступ:
- iSCSI
- Fibre Channel
- Поддержка RAID: 0, 1 (0+1), 3, 5, 6, 10, 30, 50, 60
- SSD кэш
- Тиринг
- Поддержка интеграции с облачными провайдерами:
- Amazon S3
- Microsoft Azure
- Google Cloud Platform
- Alibaba AliCloud
- OpenStack
- Файловый доступ:
- CIFS / SMB
- AFP
- NFS
- FTP
- WebDAV
- Object Protocol REST API
- Openstack Swift
Контроллеры могут работать как в симметричном, так и ассиметричном режиме Symmetric active/active. Отказоустойчивость на уровне контроллера для файловых шар работает в ассиметричном режиме, т.е. дисковый пул привязывается к одному из контроллеров и доступ к нему можно получить только через этот контроллер. Ко второму контроллеру пул перепривязывается только в случае выхода из строя «родительского» контроллера. Соответственно отказоустойчивый доступ к шаре необходимо обеспечивать на сетевом уровне. Представители вендора говорят о том, что в версии ПО, которая появится в следующем году, будет переработан механизм работы с дисковыми пулами для файловых шар.
Режимы работы с облаками:
- Cloud Cache
- Cloud Tiering
- Cloud Backup
В общем и целом — это именно то универсальное и недорогое хранилище, которое многим было бы интересно получить у себя. Учитывая отсутствие вендор-лока на диски данное решение по цене становится крайне привлекательным. Но тут все его плюсы и закончились.
Сразу после приезда и первоначального конфигурирования системы массив был отправлен в ЦОД для проведения тестов производительности и отказоустойчивости. Тут то и начались первые звоночки.
Началось всё с документации, а в частности, с расширенных настроек портов.
В документации сказано «In a dual-active controller configuration, you need to manually create more Slot A or Slot B Channel IDs to distribute the workload between partner controllers.” При этом сколько и каких, в документации никак не сказано. Проблема усугублялась тем, что изменение этих параметров требовало перезагрузки контроллера. А “by design” Infortrend перезагружает оба контроллера одновременно!
«In WebGUI, if you press that «reset button» it will reset both controllers at the same time.”
Соответственно передав массив в продуктивную среду — изменение данных параметров будет сопряжено с простоем сервиса, что требует проведения регламентных работ и прочий геморрой. На вопрос к саппорту — что же тут следует настраивать, получили ответ: «Normally, we suggest to the customer do not change any parameter setting in the «Advance Setting». As much as possible use the default setting to optimize the performance.”
«It is not necessary to change the parameters of Advance Setting.”
Конечно задав им ещё пару раз эти же вопросы — мы более-менее получили нужные ответы, но на этом всё интересное не заканчивалось. Ещё же были и расширенные настройки хостов.
Первым пунктом нас смутили параметры «Max concurrent host-LUN connections”, ведь у нас предполагается подключение СХД к целому кластеру и с десятками хостов.
«MAX concurrent host-LUN connections», the parameter is obsolete in current firmware.”, на мой вопрос — будет ли этот параметр использоваться в будущих прошивках или просто его уберут из настроек, что произойдёт, если данную настройку вернут в следующих прошивках и тд, мне предложили просто для нас специально в следующей прошивке увеличить это число, если текущих значений нам не хватает.
Уже на этом этапе у меня сложилось ощущение, что всё общение с саппортом будет очень тяжёлым для нас. То ли они в целом так работают, то ли мой русско-английский для их тайваньско-английского слишком не понятен, но постоянно складывалось ощущение, что они нас не понимают, мы задаём какие-то странные вопросы, проводим какие-то тесты, нам не хватает информации в документации.
Следующей нашей задачей было проверить отказоустойчивость системы. Банальное поочерёдное вынимание контроллеров и наблюдение за их переключением. Мы даже завели кейс, где сообщили саппорту, что планируем это сделать, на что в ответ нам начали рассказывать про необходимость использования Multipath.
Тестирование проводили в двух режимах:
1. Asymmetric active/active: мы создали несколько пулов, часть привязали к контроллеру А, часть к контроллеру В. При этом на хостах мы видели только 2 активных пути и не видели резервных, как должно было быть по логике и мануалам. Вынули первый контроллер и у нас пропали все (!!!) пути до всех томов на разных пулах, несмотря на то, что они были привязаны к разным контроллерам!
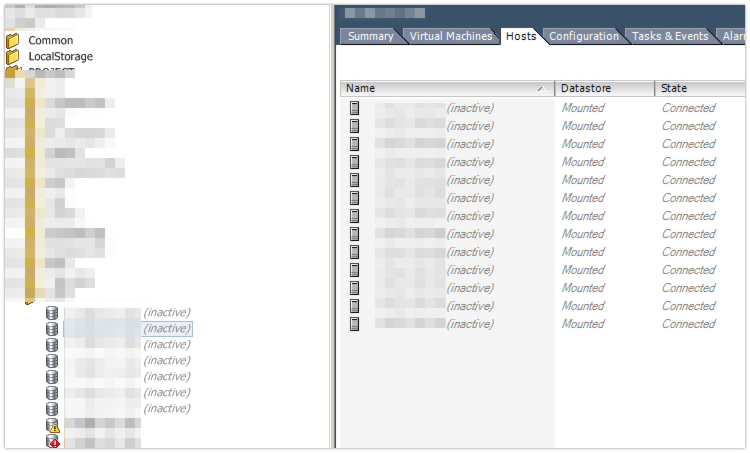
все 7 лунов, находящихся на 7 пулах у нас отвалились. 1, 3, 5 и 7 пулы были привязаны к контроллеру А, 2, 4, 6, к контроллеру В. 15, 17, 19 и 21 луны соответственно на 1, 3, 5 и 7 пулах, остальные на 2, 4 и 6.
Когда мы вернули контроллер А на место, у нас поднялись все пути, статус массива вернулся к здоровому и мы вынули контроллер В. При этом у нас ни один путь не упал. Получается несмотря на то, что половина пулов у нас была привязана к контроллеру В, пути всё-равно шли через контроллер А. Когда мы вернули контроллер В на место, состояние массива снова вернулось к здоровому состоянию.
2. Symmetric active/active: Я создал один пул, на нём разместил один лун и презентовал нашему кластеру. Лун был доступен по всем 4 путям
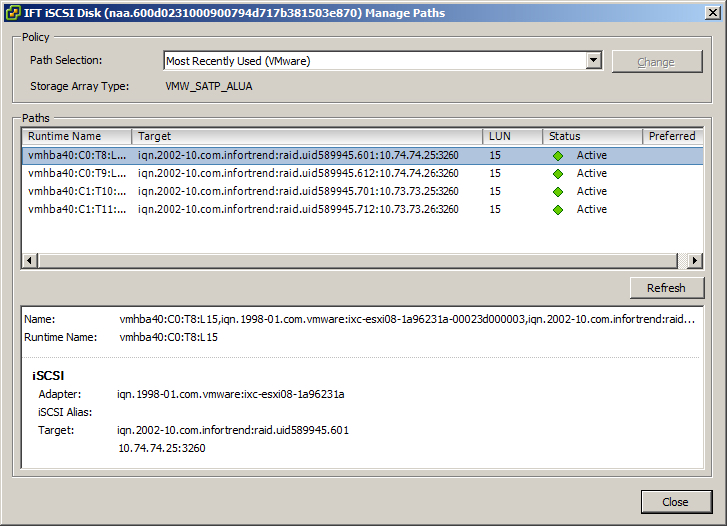
мы вынули контроллер А и у нас предсказуемо отвалилась половина путей
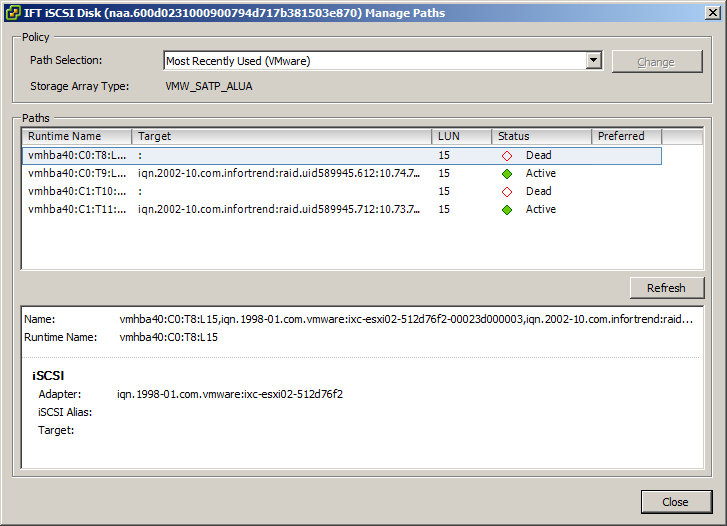
Затем мы вернули контроллер А на место и примерно через 2 минуты массив стал полностью недоступен. При этом статус массива был в состоянии Shutdown. Сервисный адрес не пинговался, все пути до луна с хостов отвалились и соответственно все операции I/O остановились. CLI так же был недоступен. Об этом мы сообщили вендору и перезагрузили массив пока инженер был у нас в ЦОДе. Саппорт попросил собрать логи, что мы и сделали и к нашему удивлению сообщил, что за тот промежуток времени, в который мы проводили тестирование — в логах ничего нет. Ни об отказе массива в целом, ни об изъятии из массива контроллера. Саппорт с умным видом задавал какие-то бесполезные вопросы, типа «сколько хостов у нас подключено к схд, сколько vm на датасторе», запрашивали снова логи, кор-дампы, просили повторить тест (и он заканчивался так же каждый раз) и продолжали говорить, что в логах ничего нет. Они даже сняли нам видео, как проделывают «то же самое, и у них всё работает». Устав спорить и что-то доказывать саппорту, мы совместно с инженером в ЦОДе сняли аналогичное видео
и только после его просмотра, саппорт подумав выходные, и, видимо, воспроизведя всё ещё раз у себя (а как они это делали до этого?), подтвердили что им удалось воспроизвести проблему.
«For the update, we can duplicate the issue in our lab as you did on Active-Active Mode.
In the meantime, our team is still trying to find what is the root cause.
As per to our investigation the problem occurs when syncing the controllers.»
При этом про проблему с путями в режиме asymmetric active/active они вообще как будто забыли.
Полтора месяца мне потребовалось с ними общаться, чтобы убедить в наличии такого крупного бага в системе. При этом у меня складывалось впечатление, что саппорт считал меня просто за дебила, особенно когда не видел моих действий в логе и много раз уточнял — точно ли я что-то делал на самом деле и с тем ли массивом я производил работы.
После этого им потребовалось 3 недели, что бы выпустить новую прошивку 1.33G.20, которая должна была исправить этот баг.
В тот же день эта прошивка была установлена на массив и вечером мы начали проводить испытания. После вынимания первого контроллера и возврата его на место, массив перешёл в состояния Shutdown, но продолжил работать, доступ до веб-интерфейса потерян не был, I/O не остановилось и всё выглядело вполне в рабочем состоянии. Мы провели операцию несколько раз, но недоступность массива так и не проявилась. Мы оставили его под нагрузкой на все выходные. В понедельник утром, я попытался пересобрать пулы на СХД, но понял, что в состоянии Shutdown массив не даёт выполнять операции с ними. Я перезагрузил его удалённо, загрузился он уже во вполне рабочем состоянии, после чего я снял логи и отправил саппорту вместе с описанием всего произошедшего. Но не тут то было, саппорт снова не нашёл в логах никаких операций с контроллером за указанный момент времени! После чего они решили устроить со мной конф-колл, где 10 минут показывали мне дырку в наших логах, которые заканчивались установкой обновления на массив и начинались в понедельник утром с загрузки массива. При этом уверяли меня несколько раз, что теряться логи у них в принципе не могут, на что я попытался возразить, что такое уже было, но мои доводы были проигнорированы. Мы попытались воспроизвести этот тест снова, я даже по привычке уже включил запись с экрана, но в этот раз массив успешно пережил несколько вынимание обоих контроллеров, каждый раз возвращаясь в нормальное состояние Healthy. Это расстроило меня ещё больше, т.к. плавающая проблема — это ещё хуже. При этом изменилось и поведение массива в режимах Symmetric/Asymmetric active/active, теперь независимо от того, какой режим установлен для пула — с хоста мы видим активными все пути до массива и ни одного пассивного через второй контроллер. При этом оставались мелкие баги с подвисанием веб-сервера схд, на котором крутится веб-интерфейс. Потерей логических девайсов при удалении пула и невозможность привязать диски из этого логического девайса к новому пулу. И снова поддержка (а вместе с ней уже и куча региональных менеджеров) заявляет: «Аномальное сообщение, которое он обнаружил во время его тестирования, мы не встречали в нашей среде.»
В итоге 7-го мая мы предоставили им удалённый доступ к массиву, они сняли всё те же логи, что я им уже отправлял (видимо они уже не только дураками нас считают, но и подозревают в подмене логов) и написали:
«We will have engineering team to check it right away and let you know the results.». С тех пор — уже неделю, мы не получали от них больше никакой информации. При этом, дистриб, который находится в копии всей этой переписки никак не хочет решать со своей стороны — ни возврат денег, ни замена массива на другой, пока с этим не согласится сам Infortrend. Представитель Infortrend считает, что они выпустили в обещанный срок (20 апреля) прошивку, которая закрывает проблему с failback’ом контроллера и остальные проблемы, это уже не так важно или это не мешает нам как-то начать использовать их продукт (а мы уже не раз им прямо заявляли, что задержка перед внедрением в продуктив Enterprise устройства на 2.5 месяца — это вообще ни разу не хорошо). В итоге нами было принято решение забить на всю эту ситуацию и перестать тратить на него время. Массив будет использоваться под различные малокритичные данные, которые могут выдержать несколькодневного простоя.
От себя хочу сказать — никогда не стану больше связываться с устройствами данного вендора. Ещё забавный момент — во время нашего длинного диалого с саппортом, мне в почту написал маркетолог компании Infortrend, предложив посотрудничать и сделать для них несколько обзоров. Я описал ситуацию и, думаю, они больше не станут ко мне обращаться.
Не рассказать эту историю я просто не мог. Источники, близкие к Infortrend рассказали мне, что системы серии GS достаточно новые и в них ещё хватает багов. И я даже могу это понять. Я не могу принять ситуацию, что саппорт всячески делает вид, что это мы что-то делаем не так, нам приходится их в чём-то убеждать, даже в очевидных вещах с теми же пропадающими логами (“никогда такого не было и вдруг опять” (с)) и что не саппорт бегает за нами в попытке решить проблему, а мы их постоянно пинаем.
И да, представитель Infortrend, с которым мы так же общались — Davit Beybutyan, видимо с подачи нового маркетолога, всегда готов пообщаться с вами в корпоративной ветке на форуме iXBT.