NetApp для самых маленьких: Data Protection

И так, в моём цикле статей «NetApp для самых маленьких» я подошёл к наиболее обширной теме о технологиях NetApp — защита данных. Стоит сразу отметить, что массивы на ONTAP предоставляют пожалуй наибольшее количество возможностей, среди всех конкурентов. При этом компания только продолжает развивать это направление всё сильнее. Сегодня будем погружаться во все возможности по защите данных.
SyncMirror
RAID-DP обеспечивает избыточность на случай, если мы потеряем до двух дисков в группе RAID в совокупности.
Multi-Path High Availability (MPHA) обеспечивает избыточность наших подключений от контроллеров к дисковым полкам. У нас есть два соединения SAS, идущих к нашим дисковым полкам, поэтому, если мы потеряем какое-либо соединение или любую из полок, мы все равно сможем добраться до других работающих полок.
Но что делать, если мы хотим защититься от выхода из строя целой полки? SyncMirror позволяет реализовать зеркалирование на уровне конкретного агрегата нашей системы, т.е. пишет данные сразу на 2 набора накопителей. Преимущество, которое мы получаем от этого, состоит в том, что мы получаем избыточность данных. Если мы потеряем дисковую полку, мы не потеряем наши данные. Недостаток в том, что это будет дороже, потому что вам понадобится вдвое больше дисков.
Два разных зеркальных набора дисков, составляющих агрегат SyncMirror, называются плексом (Plex). В данном случае — каждый плекс это набор дисков из разных полок. Обычный агрегат без SyncMirrored содержит только один плекс.
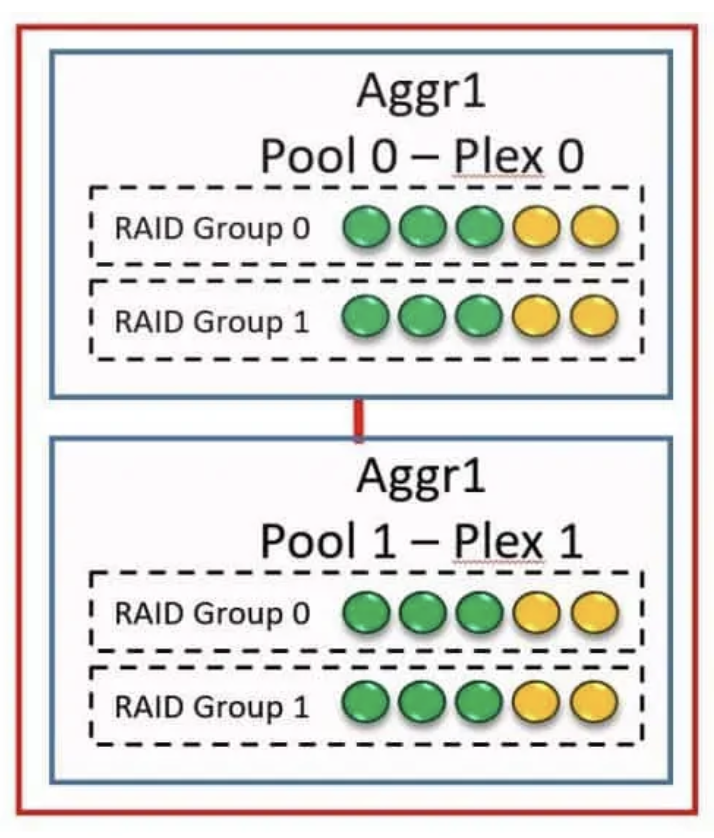
Таким образом мы защищаем наши данные от выхода из строя целой полки и остановки наших сервисов.
SnapMirror
SnapMirror — это можно сказать «базовая» технология репликации в системах под управлением ONTAP. На базе неё строятся различные решения, обеспечивающие геораспределённое хранение данных, такие как Load Sharing Mirrors, Data Protection Mirrors, SnapVault о которых мы будем говорить подробнее далее. Как следует из названия, SnapMirror создает реплику или зеркало ваших данных во вторичном хранилище, из которого вы можете продолжать обслуживать данные в случае аварии на первичном сайте. Когда вы запускаете репликацию с помощью механизма SnapMirror, исходный том будет доступен для чтения и записи, а том-зеркало на второй площадке будет доступен только для чтения. Это позволяет сохранить целостность данных. Первоначальная репликация с исходного тома на том назначения представляет собой полное копирование данных, ве последующие репликации будут инкрементальными. Система использует снэпшоты исходного тома для обновления тома назначения. Обновление данных происходит автоматически на базе созданного расписания репликации, но может быть запущено и вручную. Исходя из этого мы можем сделать вывод, что репликация у нас асинхронная и минимальное время репликации составляет одну минуту.
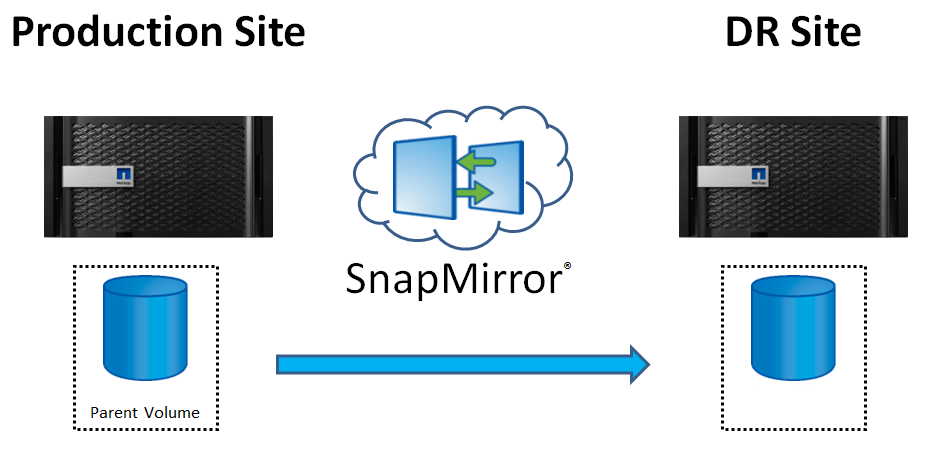
SnapMirror это не всегда геораспределённая репликация, она может быть организована и в пределах одного кластера. Репликация производится на уровне SVM.
Как же работает репликация? В момент запуска репликации, создается новый снепшот тома. Текущая копия снепшота SnapMirror сравнивается с предыдущим снепшотом SnapMirror, а затем постепенно синхронизируются только изменения из источника в место назначения. Если какие-либо файлы были изменены, он не реплицирует весь файл. Репликация выполняется на уровне блоков, поэтому передаются только измененные блоки. Репликация поддерживается как для файловых шар, так и для блочных лунов.
Одной из фишек данной технологии можно назвать возможность для миграции данных со старой системы на новую. Так же стоит отметить, что реплицируются только изменения произошедшие с последнего момента репликации, т.к. инкрементально, и при этом сохраняется дедупликация и компрессия, которые произведены на основной системе, что так же сокращает объём передаваемых данных.
Так же стоит отметить, что системы на разных площадках не всегда должны быть идентичными. Допустим в наш DR входит не весь объём наших виртуальных машин, которые крутятся на основной площадке и создают нагрузку на систему хранения данных, а только критичные сервисы в объёму 20-30% от общего числа. Соответственно, на второй площадке может стоять более простая система, которой достаточно хранить и обеспечивать производительность только части инфраструктуры.
Load Sharing Mirrors
Вообще данная технология не про защиту данных, но из-за её механизма реализации, она позволяет так же защититься от выхода из строя целого набора накопителей и потери данных. И так представим, у нас есть массив NetApp и некая шара на нём. По тем или иным причинам не достаточно производительности данной системы. Возможно мало накопителей, портов ввода-вывода или не хватает производительности контроллера. У нас есть возможность расширить данную систему горизонтально, объединив несколько контроллеров в один кластер. Чем в данном случае нам может помочь Load Sharing Mirrors? В рамках данного единого кластера мы сможем сделать зеркало данной шары, который сможем сделать доступное через вторые контроллеры нашего кластера, которые будут располагаться на отдельной дисковой группе второй пары контроллеров, тем самым мы увеличим производительность. Но стоит отметить, что зеркальная копия (или копии, которых может быть несколько) будут доступны только на чтение. Все операции записи будут происходить только на основную шару. Соответственно получается ситуация, что если по какой-то причине наша основная шара становится не доступна (предположим умерли контроллеры, развалились все дисковые полки и вообще полная недоступность и потеря данных), во-первых, мы не теряем наши данные — у нас есть одна или несколько копий этих данных, которые остаются в неизменном виде и мы можем из них восстановиться. Во-вторых, наши клиенты не теряют доступ к данным. Да, они не смогут записать новые данные, пока мы не восстановим основную шару, но по крайней мере у них будет доступ на чтение. Load Sharing Mirrors работает только в рамках одного кластера и нельзя сделать зеркало на другом кластере.
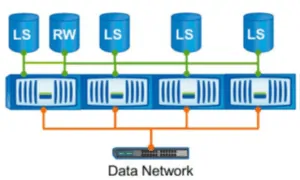
Чтобы получить доступ на запись, клиент должен обратиться к шаре по специальному пути, например для «share» это будет «/.admin/share». Исходя из сложности данного процесса можно сделать вывод, что Load Sharing Mirrors подходят для шар, которые в основном используются только на чтение, а изменения на них записываются крайне редко. Load Sharing Mirrors доступен для файловых шар CIFS и NFS v3 (именно 3-й версии, 4-я не поддерживается, так же как и блочные луны).
SnapVault
Реализация резервного копирования данных от компании NetApp. Позволяет хранить снепшоты одной СХД на другой системе, т.е. резервная копия на уровне луна. А учитывая, что системы ONTAP так же поддерживают NDMP, таким образом можно собирать данные с продуктивных систем и перемещать их на ленты, получая таким образом многоуровневую систему резервирования данных. При этом одна система, принимающая снепшоты, может работать с несколькими продуктивными СХД, за счёт чего мы можем получить централизованное хранилище резервных снепшотов, которое так же может быть гео-распределённым, а так же может сочетаться с применением SnapMirror.
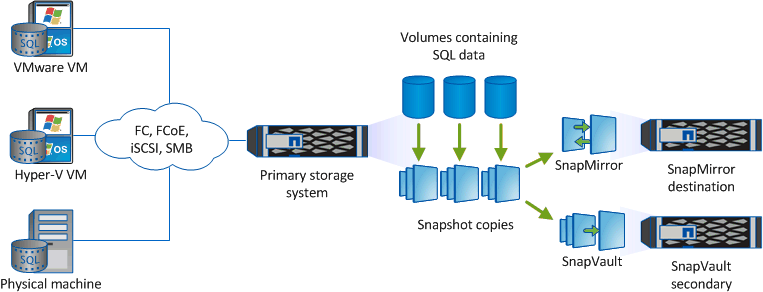
При этом системы могут быть различны по конфигурации как контроллеров, так и дисковых ресурсов. Например, можно использовать недорогие NL-SAS диски для хранения большого количества продуктивных данных, которые при этом будут располагаться на SSD на продуктивных системах. Примечательно то, что данная технология основана на базе SnapMirror и даёт те же преимущества репликации инкрементов и экономии за счёт дедупликации и компрессии.
Кто-то может спросить — так в чём же отличие SnapVault от SnapMirror? Самое простое объяснение :
SnapMirror — это технология аварийного восстановления, предназначенная для аварийного переключения с основного хранилища на вторичное на географически удаленной площадке. SnapVault — это технология архивирования, предназначенная для репликации снэпшотов с диска на диск и глубоким сроком их хранения (месяцы-годы).
Так же поддерживаются каскадные решения, когда мы используем не две, а более систем: Первичная система -> snapmirror; Вторичная -> snapvault; Третичная.
SVM-DR
Резервирование требуют не только целиком системы или отдельный луны, но и такая сущность, как SVM со всем её содержимым.
Не буду писать про него отдельно, есть прекрасная статья Дмитрия Березенко «NetApp ONTAP: SnapMirror for SVM«.
MetroCluster
Гео-распределённый отказоустойчивый кластер построенный на базе систем хранения данных NetApp FAS, такой кластер можно представить себе, как одну систему хранения, растянутую на два сайта, где в случае аварии на одном из сайтов всегда остаётся полная копия данных. Главным здесь является задержка между площадками, которая по рекомендациям не должна превышать более 5мс. Я в своё время уже рассказывал о том, как мы строили метрокластер на базе NetApp в FC его реализации, когда дисковые полки подключаются через FC-SAS бриджи, но так же есть реализация и по IP.
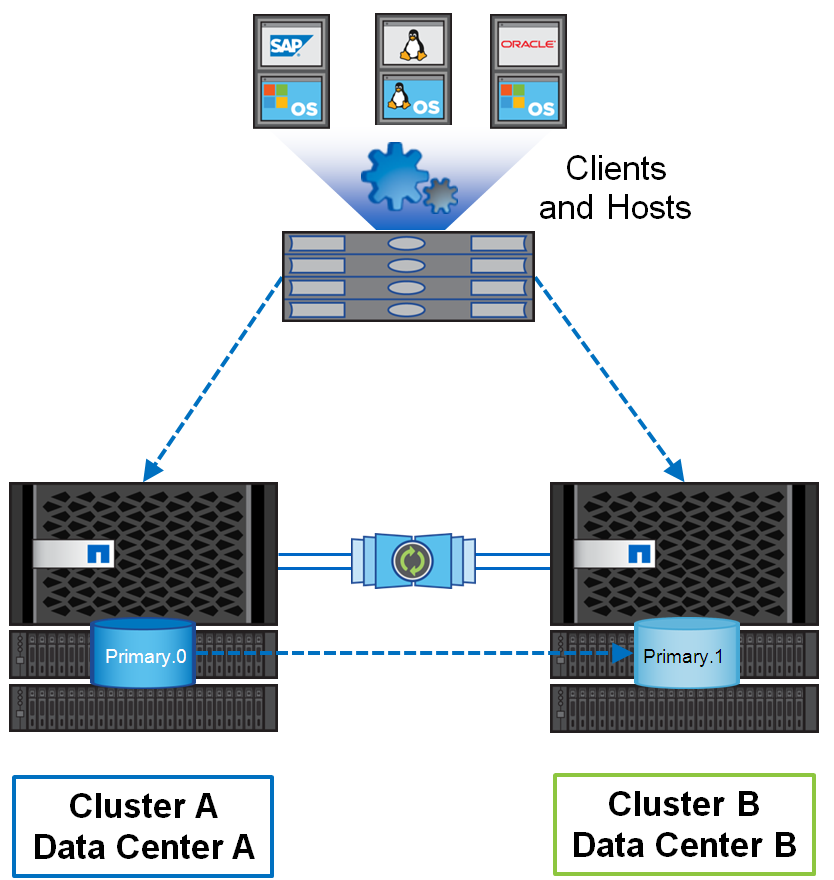
Основное отличие данного метрокластера от конкурирующих решений состоит в том, что репликация данных происходит на уровне дискового аггрегата. По мнению компании NetApp это позволяет сократить издержки, что приводит к более низкому отклику. Стоит отметить, что помимо сложности в реализации, это ещё и наиболее затратное решение, т.к. требует выделенных коммутаторов для репликации, которые ещё должны быть и «совместимы» с данным решением.
Какие возможности даёт использование метрокластера:
- Защита от сбоев оборудования, сети или площадки благодаря прозрачному переключению
- Устранение плановых и незапланированных простоев
- Обновление аппаратного и программного обеспечения без прерывания работы
MetroCluster — это кластерное решение active-active, которое устраняет необходимость в сложных сценариях отработки отказа, перезагрузках сервера или перезапуске приложений. Но следует отметить, что помимо самого метрокластера на уровне СХД мы должны использовать и встроенные возможности среды виртуализации или гостевых операционных систем. Типичный пример в связке с системой виртуализации выглядит так — виртуальная машина работает на площадке А и реплицируется средствами СХД, при этом у нас есть растянутый на 2 площадки кластер. Соответственно, при падении площадки А, наш растянутый кластер виртуализации видит, что ВМ стала недоступна, при этом у него есть активные пути до второй СХД, где лежит реплика этой виртуальной машины и он просто её перезапускает. Обычно на это уходит несколько секунд и всё время восстановления у нас занимает лишь время загрузки операционный системы и поднятия сервисов внутри ВМ. Так как данные у нас во время репликации писались на обе площадки одновременно — потери данных не происходит (тут есть оговорки конечно, относительно данных, которые были в памяти виртуальной машины, поэтому принято говорит, что RPO стремиться к 0, но не всегда ему равен).
Для обеспечения оперативного переключения систем и решения проблемы split brain используется 3-я площадка с арбитром, которому в обычном состоянии ноды кластера передают информацию о себе, что позволяет определять, когда какая-то из систем становится недоступна.
SnapMirror Business Continuity
Довольно новое решение в ONTAP, появившееся в ONTAP 9.8 и работающее только на all-flash моделях NetApp — AFF и ASA. Позволяет строить метрокластер на уровне отдельных лунов (как это предлагают большинство конкурентов). При этом для репликации используется всё тот же SyncMirror в синхронном режиме.
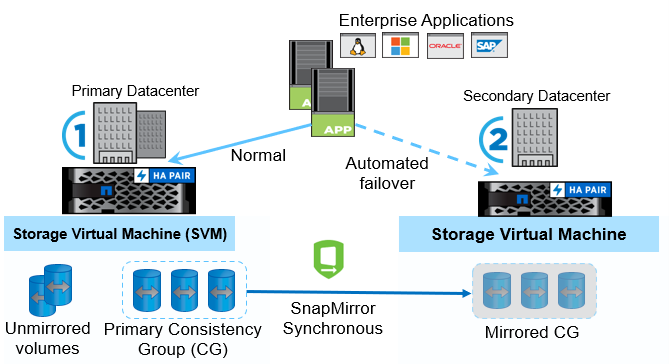
Поддерживается не только репликация отдельных лунов, но и группы консистентности, когда наше приложение раскидано по нескольким лунам и мы хотим их одновременной репликации, чтобы получить согласованные данные на определённый момент времени. Так же как и другие решения, стремиться к обеспечению нулевого RPO/RTO. В целом, несмотря на несколько иные названия, SM-BC повторяет архитектурно MetroCluster — так же вторичные луны находятся в состоянии read-only и имеют такой же идентификатор, как и на основной системе, что позволяет прозрачно переключаться при потере основной системы. Так же используется медиатор на 3-й площадке, которому ноды сообщают своё состояние и на основе этих данных медиатор принимает решение о переключении в случае недоступности основной системы. SM-BC можно назвать облегчённой версией MetroCluster’а, когда мы на любой системе (имея соответствующую лицензию) можем организовать геораспределённую защиту данных, при этом нам не понадобится дополнительное оборудование или перекоммутация. Так же построение этого решения является более простой задачей, чем организация классического MetroCluster’а.
Теперь отдельно про программное обеспечение, работающее не на СХД, но в связке с ней
SnapCenter
Это программный продукт, компании NetApp для централизованной защиты данных и управления клонированием. По сути это ПО для резервного копирования и восстановления данных, который использует в качестве сорса и таргета снепшоты, и самое главное — позволяет гранулярно работать с данными внутри этих снепшотов. Поддерживаются различные платформы:
- Windows/Linux/UNIX
- SQL Server/SAP HANA/Oracle
- Exchange
- VMware vSphere
Так же есть портал NetApp Storage Automation Store, на котором можно найти кастомные плагины, например для MySQL, DB2 и MongoDB разработанные сообществом.
Архитектурно решение состоит из 2 компонентов — сервера управления и плагина для хоста

Лучше всего демонстрировать работу таких вещей наглядно, поэтому рекомендую хоть и старый, но очень хороший вебинар от компании Netwell NetApp SnapCenter for SQL.
Если же централизованное решение вам не нужно, ввиду специфики вашей инфраструктуры, то вы можете использовать SnapDrive, который устанавливается на хост и предоставляет аналогичный функционал, но управляющийся с этого конкретного хоста и только для него.
По итогам этого текста можно сделать обоснованный вывод, что системы под управление ONTAP предлагают огромный набор средств для резервирования данных и обеспечения отказоустойчивости. На каком бы уровне СХД вы не захотели построить зарезервировать основную систему — для этого есть подходящий инструмент.
Если статья вам зайдёт и будет пользоваться популярностью, то я найду в себе силы написать вторую часть, которая уже будет содержать в себе практические приёмы по настройке (насколько это позволит ONTAP Select).