
Столкнулись с такой проблемой и разбирались с её решением, но для начала, для тех кто не знает, что такое VAAI XCOPY.
VAAI — vStorage API for Array Integration, как видно из названия — API VMware для работы с СХД. Большинстве современных СХД поддерживает данную технологию. В частности XCOPY (иногда называют Full Copy) позволяет мигрировать данные с одного датастора на другой без утилизации чинков между хостом и СХД (даже если датасторы находятся на лунах разных производителей СХД).
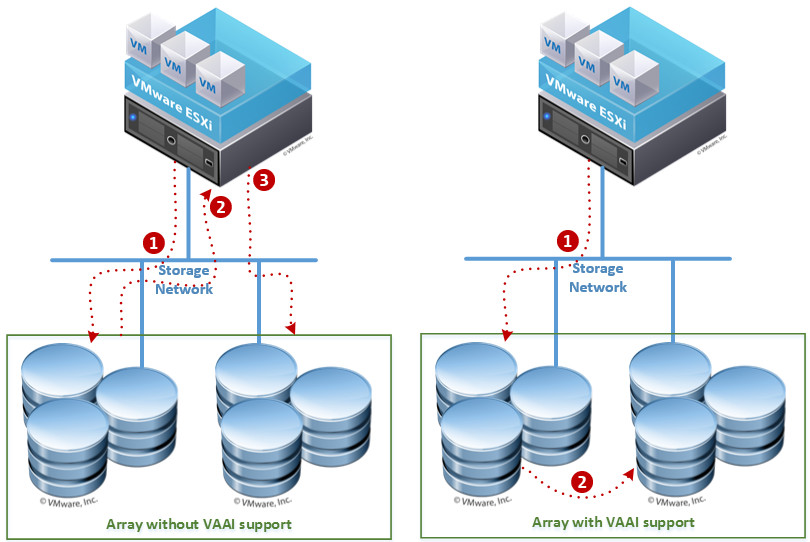
Конечно это очень классный функционал, который не требует дополнительных настроек или действий со стороны администратора и работает автоматически при операциях Storage vMotion, если СХД поддерживает VAAI. Гипервизор сообщает посредством API какие блоки на датасторе занимает ВМ, которую необходимо перенести и все операции по он производит уже самостоятельно. Соответственно не нагружается SAN и нет лишней нагрузки на CPU хоста ESXi.
Вот и при миграции виртуальных машин с одного датастора на другой, находящихся на массиве Huawei Dorado мы столкнулись с тем, что утилизация CPU массива в этот момент выросла до 90+% и задержки на продуктивных лунах возросли.

Причина в механизме ограничения нагрузки на данные операции внутри массива. По умолчанию для операции full_copy задан приоритет highest.
Проблема в том, что на уровне СХД просто сменить данный приоритет не получится — по заверениям саппорта full_copy job_information не поможет. Пришлось обратиться за разъяснениями в R&D Huawei. Процитирую ответ целиком:
Principle and mechanism:
The storage background full copy triggers flow control based on the I/O size. Currently, the full copy speed is high because the overload is not severe. Therefore, the full copy speed is not controlled to a lower speed.
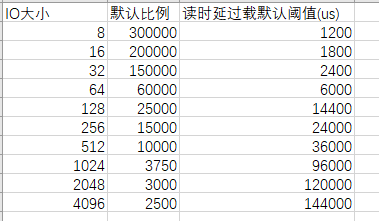
The default threshold for triggering read latency overload is 1.2ms. The 1.2ms threshold is for 8 KB I/Os. The threshold varies with I/O overload latency. The larger the I/O, the higher the threshold.
Now read I/Os are large (30K–67K), and the corresponding read overload triggering delay ranges from 2.4ms to 6ms. However, the actual maximum delay is about 3ms. Therefore, only slight flow control is triggered. Fullcopy can still run high speeds.
The latency thresholds of different models or versions may be different:
IO size, Default Scale, Default threshold
If you want to ensure a lower latency, you can run the command to change the automatic adjustment threshold to control the speed adjustment of the full copy in the background. However, you cannot directly change the speed.
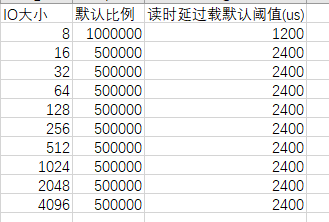
To solve this problem, we provide a command to adjust the ratio between different I/O latency thresholds. The ratio of different I/O latency to the 8 KB I/O latency threshold can be adjusted. The 8 KB I/O latency threshold is used as the reference value (1,000,000). You can adjust the relative proportions of I/Os of other sizes, as shown in the following figure.
change qos normalized_io_formula value_16kb=500000 value_32kb=500000 value_64kb=500000 value_128kb=500000 value_256kb=500000 value_512kb=500000 value_1024kb=500000 value_2048kb=500000 set_type=overload_ctrl
After this command is executed, the overload latency threshold of each I/O size changes to the following values. You are advised to adjust the overload latency threshold based on service latency sensitivity.
IO size, Default Scale, Default threshold
Изменение параметра normalized_io_formula скажется на всех операциях VAAI, в том числе на unmap и writesame, поэтому играться с параметрами стоит крайне внимательно. Либо оставить как есть, если задержки вырастают кратковременно и не очень критично.
