NetApp для самых маленьких. Часть 3

И так, нам остался последний рывок. Сегодня мы закончим настройку системы и сможем приступить к работе с данными на нашей системе.
Сегодняшняя статья будет логически разделена на 3 части:
- Блочный доступ
- Файловый доступ
- SMB/CIFS
- NFS
Дело в том, что настройка iSCSI и FC практически идентична, а вот настройка доступа по CIFS или NFS будет уже значительно отличаться от других протоколов доступа. Соответственно, в зависимости от того, какой протокол вы планируете использовать, можно перейти сразу к интересующей вас части. В версии ONTAP 9.7 появилась поддержка протокола S3 в виде Public Preview, так что уже можно в тестовом варианте его попробовать, а полноценная его работа должна появится в релизе 9.8.
Блочный
Как я говорил в предыдущей части в разделе про вольюмы — для предоставления к ним блочного доступа используются Lun’ы. Лун — это логическое представление дисковых ресурсов для вашего сервера, т.е. лун является “дисковым устройством» для вашего сервера при блочном доступе к СХД. В отличие от шар создаваемых для файлового доступа, здесь не используются namespac’ы или иерархическая структура директорий. Лун создаётся внутри какого-то определённого вольюма, но не имеет жёсткой привязки к нему, т.е. вы можете перенести лун на другой вольюм в рамках одного SVM в онлайне без простоя, а можете перенести его и на вольюм в другом SVM, но тут уже будет простой доступа к нему.
Согласно best practice — на одном вольюме рекомендуется размещать только один лун. Это позволяет более удобно и гранулярно управлять выделенными ресурсами.
И здесь я сделаю небольшое лирическое отступление и поговорю о производительности. Очень часто (и не только с системами NetApp) я (да и в Storage Discussions приходят с этими вопросами) сталкиваюсь с ситуацией, когда при тесте новой СХД администратор создаёт всего 1-2 луна и получает производительность намного более низкую, чем ожидалось. Связано это с тем, что такое количество лунов просто не в состоянии утилизировать контроллеры на 100%, особенно если мы говорим о старших моделях. Т .к. в современных СХД (да и, собственно, в любой современной системе — хоть в телефоне и телевизоре) используются многоядерные процессоры, логика работы СХД почти всех вендоров (если не всех) не позволяет использовать все ядра для обслуживания операций только одного луна. Поэтому у большинства вендоров есть рекомендации относительно того, какое количество лунов вы должны использовать для лучшей утилизации контроллеров и, соответственно, получения максимального уровня производительности. Т.к. я говорил, что луны с вольюмами рекомендуется создавать 1 к 1, следовательно, рекомендацию по количество вольюмов мы можем применить к количеству лунов.
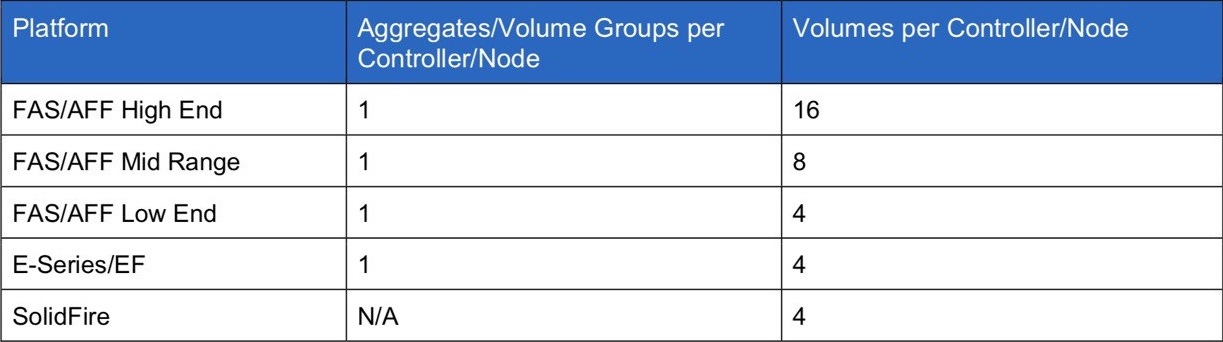
Данные рекомендации указаны для тестовых нагрузок и не стоит их использовать как мантру и всегда использовать только 4 луна для младших систем. Их может быть и 40 в зависимости от ваших задач и нагрузок. Опять-таки производительность не ухудшится, если один и тот же набор виртуальных машин (и их нагрузок) вы расположите не на 4, а на 10 лунах. На самом деле этот момент, наверное, стоило осветить именно в предыдущей части, когда мы говорили про вольюмы, т.к. в случае использования файловых протоколов у нас не будет лунов и всё вышесказанное относится и к вольюмам с файловым доступом.
Самым, пожалуй, неприятным моментом является одно досадное ограничение для луна с которым некоторые сталкиваются — его максимальный размер 16TB. Это ограничение, которое ONTAP до сих пор не перешагнула и оно смущает многих пользователей. Конечно, если следовать логике и создавать большое количество лунов, то, вероятно, вы и не столкнётесь с данной проблемой, но порой луны большего объема всё же нужны. Просто учитывайте этот момент при планировании выделения ресурсов. Конечно, есть способ обойти это ограничение — перейти на NFS.
Лирическое отступление: если вы хотите узнать больше об ограничениях и/или возможностях конкретно вашей модели или приглядеться на будущее к более старшим системам, то для этого отлично подойдёт портал NetApp Hardware Universe.
Подсказка: для работы по FC с массивами NetApp, на коммутаторах должен быть включён режим NPIV на портах.
И так, перейдём непосредственно к созданию луна:
ontap2::> lun create -vserver SVMiscsi -path /vol/vol1/lun1 -size 1Gb -ostype vmware -space-reserve disable -space-allocation enable
разберём параметры:
-vserver — в каком SVM мы создаём лун
-path — указываем по какому пути (а не на каком вольюме) будет располагаться лун. Начинается путь всегда с /vol далее идёт имя вольюма, затем имя создаваемого луна. Можно не заморачиваться с путями, которые предлагаются автоматически автокомплитом, а использовать параметры -volume и -lun.
-size — размер
-ostype — под какую ОС делаем выравнивание луна
-space-reserve — enabled или disabled, т.е. мы говорим системе — под этот лун в нашем вольюме, нам необходимо выделить пространство и ни чем его больше не занимать, т.е. ни другой лун (если вы пошли по пути создания нескольких лунов в рамках одного вольюма), ни снепшоты, никто не может занять это место. Но это будет работать только при включении space-guarantee на уровне вольюма. Если вы создаёте тонкий лун из GUI и предварительно вручную не создавали том, то он будет создан автоматически тоже тонким. Комбинация этих параметров влияет на работу технологий сжатия и дедупликации — об этом я обещал рассказать в отдельной статье.
-space-allocation — enabled или disabled, указываем поддерживает или не поддерживает данный лун thin provisioning
Есть ещё интересный параметр -use-exact-size, который позволяет создать лун именно такого размера, как вы указали, без округления для достижения лучшей геометрии луна.
Create igroup
Группы инициаторов (igroups) — это список хостов, которым в дальнейшем мы сможем презентовать наши луны. Аналогично тому, как вы задаёте список хостов для мапинга на любой другой системе. В ONTAP нет возможности презентовать лун одному серверу, без создания igroup, так что даже если у вас всего один хост — вам придётся её создать. Этот механизм используется как при работе с FC, так и с iSCSI.
iSCSI
ontap2::> igroup create -vserver SVMiscsi -igroup vmwarecluster1 -protocol iscsi -ostype vmware -initiator iqn.1998-01.com.vmware:ixc-esxi01-49769fe5
FC
ontap2::> igroup create -vserver SVMfc -igroup vmwarecluster2 -protocol fcp -ostype vmware -initiator 21:00:00:24:ff:5c:27:1e
-vserver — SVM, в котором мы создаём группу. Группы хостов являются сущностью SVM, поэтому мы должны определить этот параметр. Мапинг лунов одного SVM к лунам другого SVM невозможен. В этом случае придётся создать такую же группу инициаторов в другом SVM.
-igroup — имя группы
-protocol — протокол, по которому осуществляется доступ для данной группы
-ostype — операционная система инициаторов
-initiator — список инициаторов, через запятую. В данном случае указывается или IQN для iSCSI или WWPN для FC.
И только здесь видна разница между FC и iSCSI.
Вы можете создать несколько разных групп инициаторов рамках одного SVM. И даже инициаторы внутри этих групп могут пересекаться.
Собственно, последнее действие, которое нам остаётся сделать — это примапить наш лун к группе инициаторов
ontap2::> lun map -vserver SVMiscsi -path /vol/vol1/lun1 -igroup vmwarecluster1 -lun-id 5
-vserver — SVM, в котором мы выполняем мапинг
-path — путь до луна. Здесь также, как и при создании луна, вместо пути можно указывать -volume и -lun.
-igroup — группа к которой мапим. Примапить лун можно только в одной группе хостов.
-lun-id — параметр опциональный, мы можем вручную указать -lun-id под которым наш хост будет видеть этот лун.
В итоге у нас есть 2 луна, которые я отдал разным группам хостов и уже можно переходить к настройке самих хостов, чтобы получить доступ к лунам и начать их использование.

На самом деле, говоря про блочный доступ, я сознательно пропустил одну важную тему — NVMe протокол. Дело в том, что моя инфраструктура к нему ещё не готова. У меня пока нет ни одной сети, где бы мы планировали переходить на NVMe в ближайшее время. Соответственно, и личного опыта по настройке и работе с NVMe у меня нет, а я очень не люблю рассказывать о чём-то, что не подкреплено собственными навыками и опытом. Поэтому, если вас интересует NVMe протокол, предлагаю самостоятельно изучить данную тему в документации. NVMe protocol.
Полезные материалы по данной секции:
VMware iSCSI Datastores on NetApp Storage (without VSC)
iSCSI SAN Storage Overview Tutorial Video
Fibre Channel SAN Tutorial Part 1 — FCP and WWPN Addressing
Fibre Channel SAN Tutorial Part 2 — Zoning and LUN Masking
Fibre Channel SAN Tutorial Part 3 — Fabric Login
Fibre Channel SAN Tutorial Part 4 — Redundancy and Multipathing
NetApp ALUA and SLM Tutorial
Windows Multipathing и Data ONTAP: Fibre Channel и iSCSI
Наилучшие практики построения FC SAN
NetApp ONTAP & ESXi 6.х tuning
Файловый доступ
При работе с файловыми протоколами, в отличие от блочных, прежде чем мы сможем начать их использовать, в рамках SVM нам необходимо настроить сервер, который будет осуществлять доступ по соответствующему протоколу. Так что несмотря на то, что для блочного доступа нам не требуется создавать дополнительные логические сущности и мы перейдём к непосредственному созданию шар и работе с пользователями, первым этапом нам будет необходимо создать и настроить сервер для каждого из протоколов.
При использовании файловых протоколов у нас появляются две новые сущности — namespace и junction path.
namespace — это всё наше иерархическое древо директорий, которое мы создаём, а junction path — отдельные её ветви.
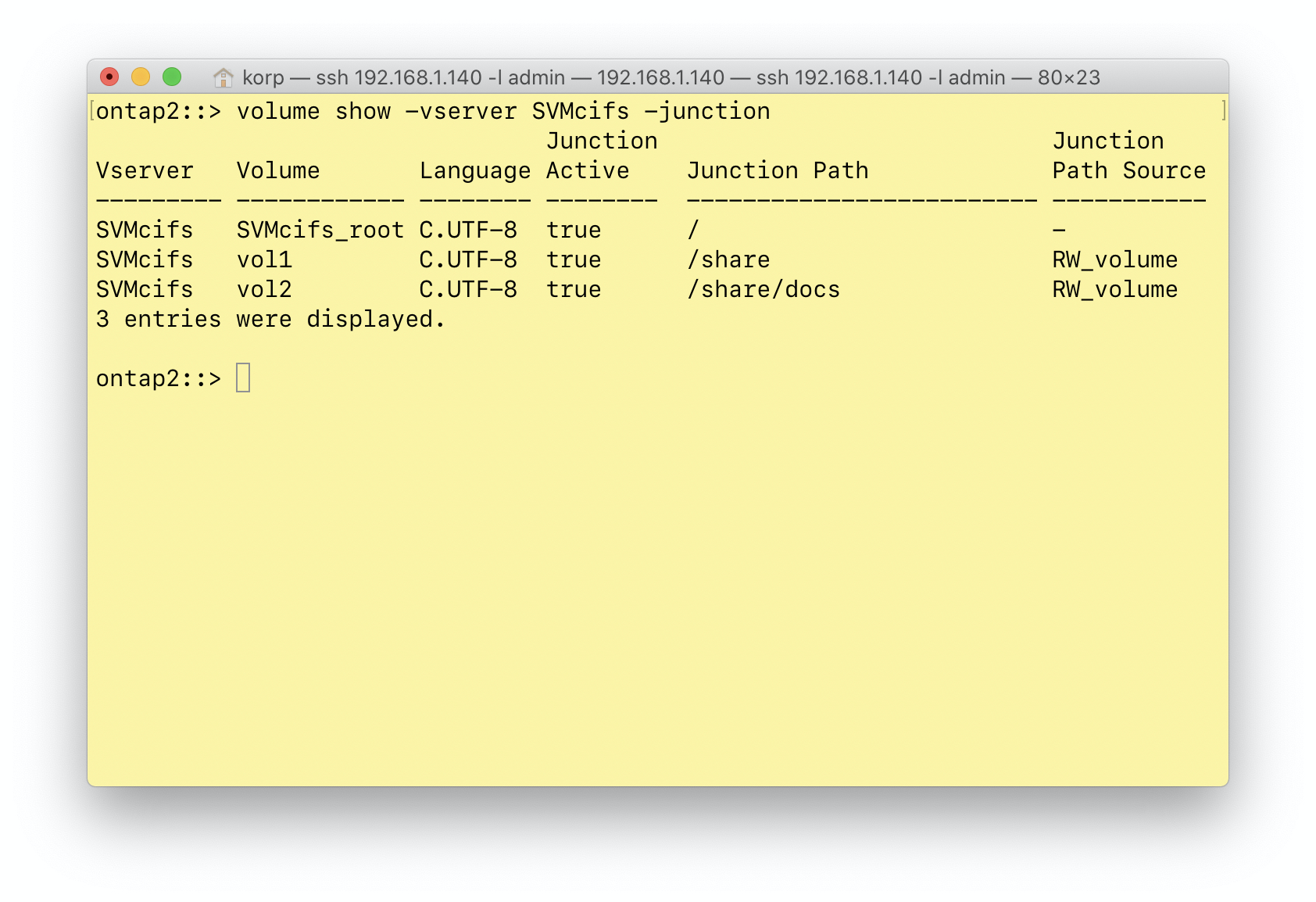
В моём примере у нас есть 3 junction path. Корнем является рутовый раздел, далее по пути /share смонтирован вольюм vol1, а по пути /share/docs смонтирован вольюм vol2. Всё это вместе и является namespace, а /share и /share/docs — junction path. Они не обязательно должны быть вложенными друг в друга. Может быть вариант /share и /docs — это уже зависит от ваших задач.
NFS
ontap2::> vserver nfs create -vserver SVMnfs -v3 enabled -v4.0 enabled -v4.1 disabled
При создании сервера мы можем указать самое главное — поддерживаемые протоколы, но, помимо этого, есть огромнейший список параметров, которые я даже не буду пытаться перечислить ввиду его размеров, а предлагаю ознакомиться со страницей в документации vserver nfs create.
Наш созданный в предыдущей части вольюм необходимо смонтировать в junction path:
ontap2::> volume mount -vserver SVMnfs -volume vol1 -junction-path /share
Теперь нам необходимо разграничить доступ и правильно настроить наши Export policy. У нас уже есть автоматически созданная политика default, но она пустая, т.е. у неё нет правил. Добавим первое правило, которое даст доступ на чтение.
ontap2::> vserver export-policy rule create -vserver SVMnfs -policyname default -clientmatch 192.168.1.0/24 -rorule sys -rwrule none -superuser none -protocol nfs
Здесь мы указываем:
-clientmatch — подсеть клиентов (или одиночный IP, или диапазон)
-rorule — права доступа на чтение для UNIX пользователей (в тестовой лабе я не использую Kerberos или NTLM. Можно указывать и несколько политик одновременно — «ntlm,krb5,sys»)
-rwrule — права на запись мы запрещаем для всех
Политика default по умолчанию уже назначена на все наши junction path, но такой уровень доступа нам нужен только для корня. Поэтому для Data шары мы создадим отдельную политику:
ontap2::> vserver export-policy create -vserver SVMnfs -policyname data
Обратите внимание на то, что в отличие от предыдущего примера, в нашей команде отсутствует слово — rule, потому что мы создаём именно саму политику (контейнер), которая будет содержать уже правила. После чего мы уже внутри неё создаём необходимые правила (их может быть и несколько и они и имеют наследование).
ontap2::> vserver export-policy rule create -vserver SVMnfs -policyname data -clientmatch 192.168.1.0/24 -rorule sys -rwrule sys
Аналогично созданию правила в default политике:
-clientmatch — подсеть клиентов
-rorule — права доступ на чтение для UNIX пользователей
-rwrule — права на запись так же для UNIX польователей
Теперь нам остаётся привязать новую политику к нашему вольюму под данные
ontap2::> volume modify -vserver SVMnfs -volume vol1 -policy data
После чего мы уже на нашем сервере можем смонтировать нашу шару и начать работать с ней

Полезные материалы по данной секции:
VMware NFS Datastores on NetApp Storage (without VSC)
NFS in NetApp ONTAP Best Practices and Implementation Guide
SMB/CIFS
Также как и для NFS, прежде всего нам необходимо создать CIFS сервер на нашем SVM. В моей лабе нет домена, поэтому я буду работать в рамках рабочей группы.
ontap2::> vserver cifs create -vserver SVMcifs -cifs-server ontap -workgroup korphome
-vserver — в котором создаём сервер
-cifs-server — имя нашего сервера
-workgroup — тут понятно, в случае если вы хотите работать в рамках доменной инфраструктуры, используйте -domain
И так, у нас уже был vol1, чтобы смонтировать его, необходимо выполнить следующую команду — здесь я думаю, даже пояснения не нужны:
ontap2::> volume mount -vserver SVMcifs -volume vol1 -junction-path /share
Теперь нам нужно создать саму шару
ontap2::> cifs share create -share-name data -path /share
И последнее, что осталось сделать — создать пользователя. Я уже говорил, что использую вариант с рабочей группой, поэтому создаю локального пользователя. Если же вам нужна доменная инфраструктура, то предлагаю обратиться к документации, к разделу Setting up an SMB server in an Active Directory domain.
Создаю пользователя и задаю ему пароль:
ontap2::> vserver cifs users-and-groups local-user create -vserver SVMcifs korp
По умолчанию шара доступна для всех с полными правами, нам нужно это исправить, удаляем доступ для всех
ontap2::> vserver cifs share access-control delete -vserver SVMcifs -share share -user-or-group Everyone
и добавляем доступ только для нашего пользователя
ontap2::> vserver cifs share access-control create -share data -user-or-group korp -vserver SVMcifs -permission Full_Control
И теперь мы можем уже зайти на нашу шару
Полезные материалы по данной секции:
Microsoft Hyper-V с использованием SMB 3.0 в Clustered Data ONTAP: Рекомендации
NetApp ONTAP и антивирусная защита NAS
Подводя итог нашей небольшой серии:
- Диски собираются в рейд-группы, рейд-групп собираются в аггрегаты, аггрегаты привязаны к нодам, но в случае выхода из строя родительской ноды переходят под контроль партнёра.
- Ноды объединяются в кластер, кластер более чем из одной ноды должен состоять из HA пар.
- SVM не привязывается к ноде, но создание томов внутри этого SVM может быть ограничено конкретными аггрегатами.
- Несколько SVM могут использовать одни и те же аггрегаты.
- Каждый SVM со стороны хостов выглядит как отдельная СХД со своими собственными портами, FC WWNN и iSCSI iqn.
- Вольюмы и луны можно перемещать в рамках одного SVM в онлайн и мигрировать в другой SVM, но с простоем.
- Доступ к лунам и шарам может осуществляться через порты всех контроллеров.
- IP адреса и подсети могут пересекаться в разных SVM (ipspace).
- Data LIF для файлового доступа могут мигрировать с порта на порт, блочные — нет. Соответственно, для блочного доступа необходимо использовать мультипасинг со стороны хостов.
На этом данный небольшой цикл считаю оконченным. Собственно, задача по первоначальному конфигурированию системы выполнена. Но не стоит забывать, что мы совершенно не погружались в теорию работы системы и если вы всё-таки хотите знать о ней больше и разбираться — прочитать придётся ещё очень многое. Но данный цикл по крайней мере даст маршрут, которым необходимо пройти для настройки, потому что, на мой взгляд, не во всех сущностях он очевиден для новичка в СХД в целом или если вы пришли к NetApp с какой-то другой системы. Надеюсь это было позновательно и не менее полезной будет подборка ссылок.
Что ещё почитать:
Как устроена память NetApp FAS: NVRAM, Кеш и Тетрис
Разработка файловой системы для специализированного файлсервера NFS
Файловая система WAFL — «фундамент» NetApp
WAFL как основа для системы хранения в твердотельных накопителях NetApp
Описание Ethernet интерфейсов NetApp
RAID-4 / RAID-DP — превращаем недостатки в достоинства
Технология RAID DP
RAID-DP: Реализация NetApp схемы Double-Parity RAID для защиты данных
Дедупликация данных — подход NetApp
Руководство администратора: Дедупликация
Руководство по установке и настройке дедупликации в системах NetApp FAS и VSeries
Thin Provisioning — «кредитная карта» для хранилища
Руководство администратора: Thin Provisioning
Использование Thin Provisioning в системах хранения NetApp
Руководство администратора: Сжатие данных
Что такое inline data compaction?
FlashPool StoragePools
Сайзинг Flash Pool
Руководство по дизайну, установке и настройке Flash Pool
Как защитить корпоративное хранилище от вирусов-шифровальщиков снэпшотами
Snapshots — «фото на память (дисковую;)»
SnapMirror for SVM
SnapLock — Лицензионная функция для защиты данных (WORM)
FabricPool — технология экономии для All Flash хранилищ
FlashCache. Как использовать Flash в СХД НЕ как SSD?
FlexClone — цифровая овечка Долли
FlexClone: Как технология ускоряющая разработку
FlexGroups
Назад к основам: подход NetApp к гибкому выделению ресурсов
NetApp Metrocluster
NetApp MetroCluster (MCC)
К сожалению, Роман Хмелевский свернул свой блог blog.aboutnetapp.ru окончательно, и даже старые статьи из него уже не почитать, хотя там было довольно много основ, например по WAFL, RAID, компрессии, дедупликации и прочим вещам. Конечно, многие технологии уже изменились с тех пор, как он писал о них, но для начала освоения это было бы очень полезно.
И небольшая подборка полезных ресурсов:
ONTAP 9 Documentation Center
NetApp University
Hardware Universe (требуется учётка)
StorageTalks
Алексею Сарычеву огромное спасибо за подготовку этой серии статей.
Оглавление:
NetApp для самых маленьких. Часть 1
NetApp для самых маленьких. Часть 2
NetApp для самых маленьких. Часть 3