![]()
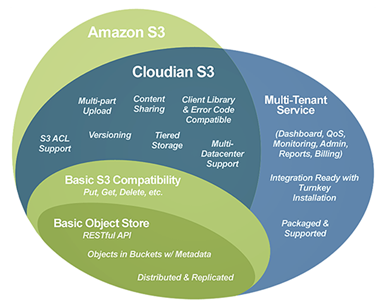
Компания Cloudian была основана в 2011 году и занимается разработкой своего продукта HyperStore для объектного хранения на основе Apache
Cassandra. HyperStore предлагается как в варианте коробочного программно-аппаратного комплекса, так и в виде ПО, работающего на стандартных x86 серверах. HyperStore довольно функционален и помимо непосредственной поддержки S3 API (о которой компания Cloudian заявляет, как 100% native S3 API support) расширен дополнительным функционалом, таким как тиринг, репликация, холодное хранение, QoS, биллинг и т.д. Данный подход делает HyperStore крайне интересным для сервис-провайдеров. И представители компании как раз и говорят о том, что большая часть их заказчиков сервис-провайдеры.
Возможности репликации между площадками позволяют строить многоуровневые схемы хранения данных — локальное, удалённое и хранение данных в публичных облаках Amazon, Microsoft и Google.
Использование протокола S3 стало популярным в последнее время благодаря невысокой стоимости хранения, что позволяет хранить в облаке как «холодные» данные, так и резервные копии. Все продукты, лидеры в области резервного копирования уже обзавелись поддержкой S3. Но не всем и не всегда выгодно хранить данные в облаках Amazon, Microsoft и Google, многие клиенты по тем или иным причинам хотят хранить собственные данные у Российских провайдеров или на собственных площадках и/или приватных облаках.
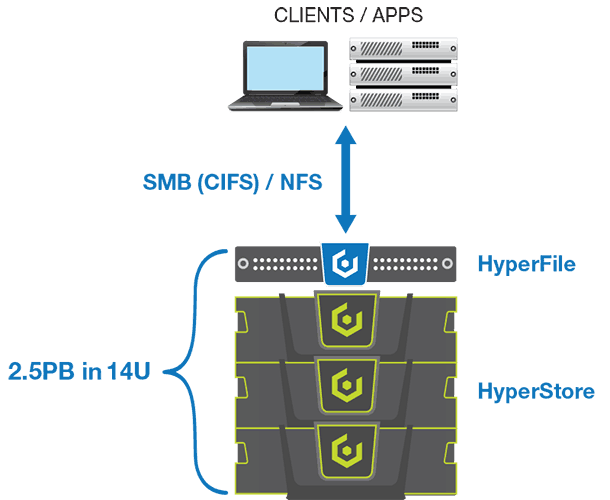
Cloudian позволяет реализовать не только поддержку S3 протокола, но и SMB, NFS и FTP. Сделано это при помощи HyperFile, который работает поверх хранилища S3, используя его API для хранения данных, что позволяет так же получить высокую доступность данных при использовании репликации и erasure coding, а также автоматический тиринг для переноса холодных данных на более дешёвые уровни хранения.
Это делает Cloudian HyperStore более гибким и функциональным решением, которое может решить любые вопросы по файловому хранению данных.
Технические характеристики аппаратных решений:
HyperStore 1500
- Form Factor: 1U
- Metadata Drives: 2 x 480GB SSD
- Data Drives: 12 x 3.5” NL-SAS HDD
- Drive Sizes: 4TB, 8TB, 10TB, 12TB
- Raw Capacity: 48-144TB
- CPU: 2 x E5-2620 v4, 8 core
- Memory: 64GB
- Network Interfaces: 2 x 10Gbe (10BaseT or SFP+)
- Monitoring/Management: CLI, GUI, API, IPMI, JMX
HyperStore 4000
- Form Factor: 2 nodes in a 4U
- Metadata Drives: 4 x 800GB SSD (2 per node)
- Data Drives: 70 x 3.5” NL-SAS HDD
- Drive Sizes: 4TB, 8TB, 10TB, 12TB
- Raw Capacity: 280-840TB
- CPU: 4 x E5-2620 v4, 8 core (2 per node)
- Memory: 256GB (128GB per node)
- Network Interfaces: 4 x 10Gbe (10BaseT or SFP+, 2 per node)
- Monitoring/Management: CLI, GUI, API, IPMI, JMX
HyperFile 1000
- Form Factor: 1U
- OS/Metadata Drives: 2 x 960GB SSD
- ZIL/SLOG Drives: 2 x 200GB SSD
- Data Drives: 12 x 3.5” SAS HDD
- Drive Sizes: 4TB, 8TB, 10TB, 12TB
- Raw Capacity: 48-144TB
- CPU: 2 x E5-2620 v4, 8 core
- Memory: 128GB
- Network Interfaces: 2 x 10Gbe (10BaseT or SFP+)
- Monitoring/Management: CLI, GUI, API, IPMI
HyperFile 2000
- Form Factor: 2 nodes in a 2U
- OS Drives: 4 x 128GB SATADOM (2 per node)
- Metadata Drives: 4 x 960GB SSD (2 per node)
- ZIL/SLOG Drives: 2 x 200GB SSD
- Data Drives: 18 x 2.5” NL-SAS HDD
- Drive Sizes: 1TB, 2TB
- Raw Capacity: 18-36TB
- CPU: 4 x E5-2620 v4, 8 core (2 per node)
- Memory: 256GB (128GB per node)
- Network Interfaces: 8 x 10Gbe (10BaseT or SFP+)
- Monitoring/Management: CLI, GUI, API, IPMI
Но если вы планируете использовать HyperFile вместе с HyperStore, то возможно развёртывание его на базе виртуальной машины VMware. HyperFile предоставляет возможность использования протоколов NFS/CIFS/FTP поверх HyperStore.
Конфигурация тестовых стендов:
- Form Factor: 1U
- OS/Metadata Drives: 1 x 8Tb SATA HDD
- Data Drives: 5 x 3.5” SATA HDD
- Drive Sizes: 8TB
- Raw Capacity: 40TB
- CPU: Intel Xeon D-1541
- Memory: 64GB
- Network Interfaces: 2 x 10Gbe (SFP+), 2 x 1Gbe
Перед нами не стояло задачи тестирования скоростных характеристик, поэтому рекомендациями по дискам и SSD под ОС/метеданные мы пренебрегли. 10Gbe интерфейсы использовались для соединения серверов в кластер, а 1Gbe под данные. Основной целью в случае этих серверов было понять возможность использования процессоров Intel Xeon-D. По нашим тестам даже при наиболее ресурсозатратных задачах — добавление/удаление ноды, восстановление потерянной ноды (Rebuilds & Rebalance), при включенном сжатии трафика (Compression), нагрузка на процессор не превышала 10% при максимальной загрузке в 110MB/s, которую нам удалось получить при заливке большими файлами.
Для хранения данных HyperStore использует 2 файловые системы:
HyperStore File System (HFS) — для хранения данных, которая использует erasure coding или репликацию, а также поддерживает 3 варианта сжатия: snappy, lz4 и zlib
Cassandra Files System — для индексов метаданных, а также может быть использована для хранения мелких файлов
Балансировка трафика осуществлялась при помощи VMware NSX по простой схеме с серверами в одном регионе
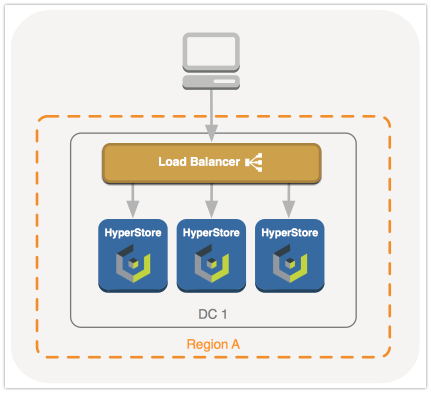
Поочерёдная перезагрузка всех нод не вызвала каких-либо проблем у системы — серверы отваливались и возвращались в кластер, сервисы переезжали с ноды на ноду. Работа по протоколу S3 осуществлялась при помощи awscli и графического CloudBerry.
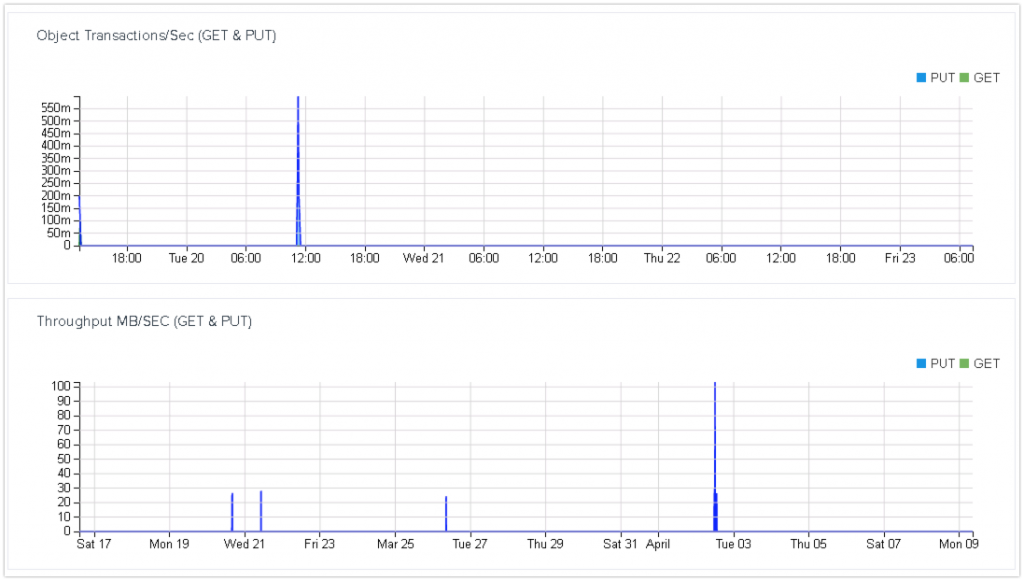
Мониторинг системы позволяет отслеживать нагрузку на стандартные компоненты внутри ОС, при этом внешний мониторинг аппаратного обеспечения отсутствует. По заявлению коллег, кто пользуется коробочными решениями HyperStore, система не в состоянии распознать даже отключения одного из двух БП и никак об этом не уведомляет администратора. При этом сбор статистики по загруженным файлам, скорости передачи данных и т.д. рассчитан на очень большие значения и по заявлениям Cloudian — могут просто не отображаться при небольшой нагрузке. Именно такое поведение графиков мы и заметили при проведении тестирования
Представители компании Cloudian заявили, что в данный момент разрабатывают отдельный продукт HyperView, построенный на базе ELK, который должен быть представлен позже и позволит лучше осуществлять мониторинг всей системы. При этом работа встроенной системы биллинга оставляет желать лучшего. Она в состоянии выставить счёт только за прошедший месяц или ранее (т.е. 28 марта нельзя выставить счёт за март), при этом настройки, связанные с количественными или денежными показателями вступаются в силу только со следующего месяца, после внесения изменений (при изменении тарификации 3-го апреля, счёт за март не изменится и изменения будут видны только с 1-го мая в счёте за апрель). При помощи API можно получить статистические данные за произвольный период, можно получить данные ratingPlan (коэффициаенты), но весь расчёт необходимо будет реализовывать самостоятельно, т.к. биллинг через API предоставляет отчёт только за предыдущий полный месяц.
В целом система пользуется высокой популярность у сервис-провайдеров благодаря отличной поддержке протокола S3 и расширенным возможностям биллинга и мультитенантности. Для нас это решение выходит ещё и довольно демократично по стоимости (естественно я не могу называть конкретные цены), на уровне которого находится лишь Scality, но с ними контакт идёт пока крайне тяжело, точнее даже не с ними, а с HPE, которые им занимаются на территории России, поэтому пока развернуть стенд со Scality и сравнить эти 2 решения у меня не представилось возможности. Что же касается лидера рынка Dell/EMC Elastic Cloud Storage, то это решение выходит слишком дорогим, как и NetApp
StorageGRID. А для нас, как для сервис-провайдера, конечная стоимость системы выливается в цену для клиентов, и, если наше решение будет намного дороже, чем решения конкурентов, мы будем просто не в состоянии конкурировать с ними на рынке. Так что математика проста, благо проблемы с мониторингом и биллингом мы можем решить собственными средствами, при наличии API.