Brocade SAN Часть 3: FCP роутинг
И так, мы плавно (и, к сожалению, очень медленно) подошли к 3-й части, в которой мы будем говорить о том, как коммутаторы работают и общаются между собой в одной фабрике. Поговорим про роутинг в FC и транках, а также о взаимодействии коммутаторов друг с другом.
Но начнём мы с того как порт устройства подключается к фабрике. Наверное это стоило описать ещё в 1-й части, но как я говорил в самом начале — мысли пока ещё путаются и структуру изложения выбрать тоже сложно.
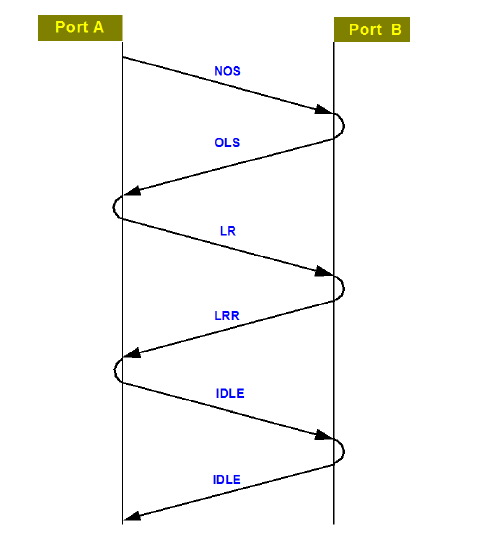
И так, у нас есть порт устройства (N-port), который хочет подключиться к фабрике — этот процесс называется Fabric Login (FLOGI)
- F-порт высылает стартовое сообщение (базовую последовательность) к N-порту NOS (Not Operational)
- Когда N-порт получает NOS, он отвечает сообщением OLS (Offline), тем самым начиная инициализацию линка.
- Далее N-порт высылает LR (Link Reset) в сторону F-порта, на что последний отвечает сообщением LRR (LR Response).
- После поднятия линка N-порт высылает FLOGI-сообщение на зарезервированный адрес 0xFFFFFE (который закреплен за Login Server’ом – некий аналог DNS сервера).
- Login Server высылает сообщение Accept в сторону N-порта. В сообщении содержится FCID устройства.
- Следующим шагом является общение N-порта с Fabric Name Server (это не какой-то конкретный коммутатор, а фабрика целиком). N-порт на него передает свои основные параметры: buffer2buffer кредиты, MTU, поддерживаемые CoS’ы и пр.
После завершения Fabric Login, в результате которого устройство регистрируется на фабрике, по требованию (когда хост хочет передать данные на другой диск) начинается процесс Port Login (PLOGI). Его целью является установление соединения для передачи данных.
PLOGI начинается с порта устройства-инициатора.
Инициатор высылает PLOGI сообщение в сторону нужной «цели», внутри которого содержатся операционные параметры.
Удаленный порт отвечает сообщением ACC, которое говорит о готовности к общению.
После этого уже начинается непосредственная передача данных.
В процессе логина устройство получает FCID. FCID — это логический адрес (FC Identificator) который используется в дополнение к аппаратным WWN.
Адрес состоит из трех частей:
- Domain ID. Идентификатор коммутатора
- Area ID. Группа портов внутри логической зоны
- Port ID
Вот теперь о DID мы и поговорим. Каждый коммутатор в фабрике имеет собственный Domain ID, который является уникальным. Всем коммутаторам в фабрике их DID раздаёт так называемый Principal switch. Выбирается он автоматически, среди всех коммутаторов фабрики, им становится или коммутатор с флагом Principal Selection Mode или выбирается по наименьшему wwn коммутатора. В процессе работы Principal switch не меняется, если он уже есть, но может поменяться, если вы каким-то образом удалите из фабрики Principal switch (к примеру, перезагрузив его). Так же principal switch можно сменить самостоятельно. Например назначив более мощный или более новый коммутатор. Имеется и рекомендация назначать principal switch’ом один из коммутаторов, находящихся в логическом центре фабрики, т. е. минимально удаленный по количеству хопов от всех остальных коммутаторов в фабрике и/или имеющий максимальное количество соединений с другими коммутаторами. Остальные коммутаторы в фабрике являются Subordinate switch. Помимо раздачи идентификаторов Principal switch является сервером времени, с которым синхронизируют свои часы остальные коммутаторы в фабрике.
Перестроение фабрики всегда серьезное событие. Оно проходит как рассылка всем коммутаторам специальных фреймов RCF (Re-Configure Fabric) или BF (Build Fabric). При рассылке RCF прекращается передача трафика во всей фабрике. BF — это более щадящий вариант, трафик приостанавливается только на том коммутаторе, с которого был инициирован процесс перестроения фабрики.
Соединение между коммутаторами называется Inter Switch Link (ISL) или Inter Chassis Link (ICS) в случае директоров. Соединение между двумя E_Port.
Линки коммутатора, ведущие от Principal Switch, называются Downstream, ведущие к Principal Switch – Upstream.
switch:admin> fabricshow
Switch ID Worldwide Name Enet IP Addr FC IP Addr Name
————————————————————————-
1: fffc01 10:00:00:05:1e:73:7c:16 10.6.200.24 0.0.0.0 «IBM_2498_24E_FSW4″
10: fffc0a 10:00:00:27:f8:de:d2:7c 10.6.200.18 0.0.0.0 >»IBM_2498_24G_FSW5»
11: fffc0b 10:00:00:27:f8:de:cc:f8 10.6.220.10 0.0.0.0 «IBM_2498_24G_FSW1″
12: fffc0c 10:00:00:27:f8:ff:1e:20 10.6.220.12 0.0.0.0 «IBM_2498_24G_FSW2»
Коммутатор отмеченный > и является Principal Switch
Для нахождения наилучшего пути хождения трафика между коммутаторами, используется протокол маршрутизации FSPF (Fabric Shortest Path First), основанный на понятии весов (cost). Коммутаторы всегда доставляют данные по пути с наименьшим весом. Общий вес пути, состоящего из нескольких ISL, равен сумме весов всех линков между коммутаторами. Вес ISL, в свою очередь, обратно пропорционален его скорости.
Для современных коммутаторов дефолтной стоимостью линка (от 2Gb/s и выше) является 500. Соответственно мы можем рассчитать такой пример: массив соединён с хостом двумя путями:
- через 2 коммутатора с линком 8Gb/s между ними
- через 3 коммутатора с линком 16Gb/s между двумя из них и 8Gb между вторыми двумя
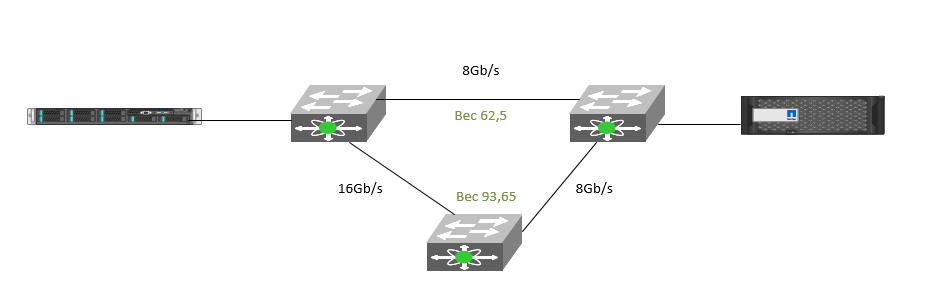
И так, мы получим стоимость путей:
- 500/8 = 62,5
- (500/8+500/16) = 93,65
При развитой SAN сети и большом количестве коммутаторов ситуация может меняться как в ту, так и в другую сторону, это нужно учитывать при планировании маршрутов.
Сервис FSPF обязательно находится на всех коммутаторах. В стабильной фабрике сбор информации о весах линков производится регулярно с 20-секундным интервалом. Каждый коммутатор по всем своим ISL рассылает короткие 64-байтные специальные фреймы HELLO (HLO). При передаче такие фреймы имеют самый высокий приоритет. Это необходимо для того, чтобы гарантировать отсутствие задержек сбора информации даже в случае значительной перегрузки линков ISL данными оконечных устройств. Информация обо всех возможных путях передачи записывается коммутаторами в персональные таблицы маршрутизации. При обнаружении разрывов каких-либо из линков FSPF сразу начинает перестройку таблиц маршрутизации. При принятии решения о перенаправлении фрейма с одного порта на другой коммутатор всегда пользуется уже готовой таблицей маршрутизации.
В случае, если между двумя оконечными устройствами существуют сразу несколько путей с одинаковым весом, решение о доставке по конкретному маршруту принимается на основании следующих политик:
- Port-based – маршрут выделяется на основании хешей номера входящего порта и DomainID следующего коммутатора. Совместно с этой политикой можно использовать статическую маршрутизацию, в которой маршруты явно образом настраиваются администратором.
- Device-based — маршрут выделяется на основании хешей FCID порта оконечного устройства источника и FCID порта оконечного устройства назначения. Удалено с версии 7.3.
- Exchange-based – маршрут выделяется на основании хешей FCID порта оконечного устройства источника, FCID порта оконечного устройства назначения и номеров FCP обмена. Опция DLS включается автоматически и не может быть отключена. Статическую маршрутизацию не поддерживает.
В современных коммутаторах Exchanged-based является политикой по умолчанию.
switch:admin> aptpolicy
Current Policy: 3
3: Default Policy
1: Port Based Routing Policy
2: Device Based Routing Policy (FICON support only)
3: Exchange Based Routing Policy
Использование опции DLS (Dynamic Load Sharing) позволяет динамически перестраивать таблицы маршрутизации при изменении топологии фабрики, что позволяет сохранить сбалансированность маршрутов. В случае перестроения топологии фабрики DLS гарантирует доставку фреймов в том же порядке, в каком они были отправлены (in-order delivery), только в рамках обменов. Для большинства приложений этого достаточно.
Политики маршрутизации отличаются друг от друга только гранулярностью разделения передачи данных по различным путям с одинаковым весом. В каждом из этих случаев пути для следующей пары источник-назначение выбираются последовательно при помощи простейшего алгоритма round-robin. Это приводит к тому, что распределение нагрузки по каналам неравномерно. Какие-то линки ISL могут быть перегружены, а какие-то будут практически простаивать. Но FCP обмены в рамках передачи данных для OLTP приложений и для резервного копирования по размеру могут очень сильно отличаться, и распределение нагрузки по каналам также может быть неэффективным. Поэтому очень важно понимать, что на уровне сети хранения не существует реальной балансировки нагрузки (load-balancing). SAN может только с той или иной степенью равномерности разделять нагрузку между каналами (load-sharing).
К сожалению, на сегодняшний момент не существует механизмов действительно эффективной балансировки нагрузки на уровне сети передачи данных. Поэтому реальные системы требуют комплексного подхода, использующего возможности специализированного ПО на уровне хостов и хранилищ данных, таких как PowerPath, HDLM, VxDMP или MPxIO.
Для диагностики подключения устройств (проверки зонинга) и путей можно использовать утилиту fcping
Она может показать как доступность самого устройства и задержки
switch:admin> fcping 50:01:43:80:24:25:6f:dc
Destination: 50:01:43:80:24:25:6f:dc
Pinging 50:01:43:80:24:25:6f:dc [0x010100] with 12 bytes of data:
received reply from 50:01:43:80:24:25:6f:dc: 12 bytes time:1120 usec
received reply from 50:01:43:80:24:25:6f:dc: 12 bytes time:1323 usec
received reply from 50:01:43:80:24:25:6f:dc: 12 bytes time:1031 usec
received reply from 50:01:43:80:24:25:6f:dc: 12 bytes time:1050 usec
received reply from 50:01:43:80:24:25:6f:dc: 12 bytes time:999 usec
5 frames sent, 5 frames received, 0 frames rejected, 0 frames timeout
Round-trip min/avg/max = 999/1104/1323 usec
А с параметром allpath покажет доступные пути с данного коммутатора до этого устройства
switch:admin> fcping —allpath 50:01:43:80:24:25:6f:dc
Pinging(size:12 bytes) destination device 50:01:43:80:24:25:6f:dc through all paths
—
PATH SWITCH1 —> SWITCH2 —> SWITCH3 STATUS
——————————————————————————————————————
1. ( 11/EMB, 11/1 )[NON-VF] ( 10/1 , 10/4 )[NON-VF] ( 1/6 , 1/19 )[NON-VF] SUCCESS
2. ( 11/EMB, 11/0 )[NON-VF] ( 10/0 , 10/4 )[NON-VF] ( 1/6 , 1/19 )[NON-VF] SUCCESS
Вывод тут вполне понятен — доступ до этого устройства идёт через 3 коммутатора, с указанием через какие порты.
Коммутаторы Brocade обладают дополнительной функциональностью, позволяющей существенно оптимизировать производительность передачи за счет более эффективного распределения фреймов данных между линками ISL. Такой процесс агрегирования нескольких линков ISL в единый канал называется транкинг (Trunking).
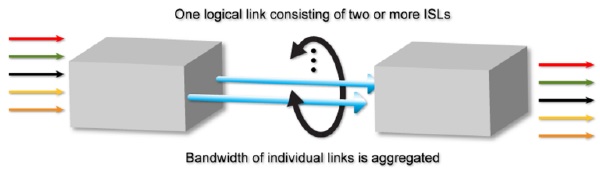
Существуют несколько требований к линкам, составляющим транк
- транк работает только на E и EX портах
- порты в одной транк-группе должны иметь одинаковые скорости
- все порты транка должны иметь одинаковый режим Long Distance Mode
- на все коммутаторы, использующие данную функцию, должна быть установлена лицензия ISL Trunking
- для обеспечения передачи фреймов в транке в той же последовательности, в которой они были переданы, очень важна величина задержки прихода сигнала между ними, что, в свою очередь, зависит от разницы в длинах самих линков ISL
Если все условия соблюдены, то при подключении линки ISL автоматически становятся членами одного транка. Если этого не произошло — первым делом рекомендуется проверить настройки портов.
В коммутаторах до максимального уровня загружается один из линков, затем следующий и т. д. Поэтому при малой нагрузке часть линков транков будут полностью простаивать. В первую очередь загружаются более короткие линки транка. При выходе из строя любого линка перестроения фабрики и, соответственно, задержки передачи не происходит. При вычислении маршрутов FSPF весь транк независимо от количества линков имеет такой же вес, как и обычные линки.
Через web-gui это видно на много проще и нагляднее, чем через консоль

Транки на коммутаторе можно посмотреть при помощи команды trunkshow
switch:admin> trunkshow
1: 0-> 0 10:00:00:27:f8:de:d2:7c 10 deskew 15 MASTER
2: 1-> 1 10:00:00:27:f8:de:d2:7c 10 deskew 15 MASTER
3: 4-> 6 10:00:00:27:f8:ff:1e:20 12 deskew 15 MASTER
5-> 7 10:00:00:27:f8:ff:1e:20 12 deskew 15
Параметр deskew относится к параметрам кабеля. Значение 15 присваивается самому короткому линку. Рекомендуется, что бы разница составляла не более 15 пунктов, что соответствует 30 метрам кабеля. Это важно, тк мы уже говорили о том, что пакеты данных отправляются через разные линки, и что бы сохранить последовательность передачи данных, задержки на каждом из линков должны укладываться в эти параметры.
Транки можно посмотреть и из web-gui

А расширенную информацию в консоли при помощи ключика perf
switch:admin> trunkshow -perf
1: 0-> 0 10:00:00:27:f8:de:d2:7c 10 deskew 15 MASTER
Tx: Bandwidth 8.00Gbps, Throughput 106.20Mbps (1.55%)
Rx: Bandwidth 8.00Gbps, Throughput 1.10Gbps (15.99%)
Tx+Rx: Bandwidth 16.00Gbps, Throughput 1.21Gbps (8.77%)
2: 1-> 1 10:00:00:27:f8:de:d2:7c 10 deskew 15 MASTER
Tx: Bandwidth 8.00Gbps, Throughput 114.05Mbps (1.66%)
Rx: Bandwidth 8.00Gbps, Throughput 1.03Gbps (15.04%)
Tx+Rx: Bandwidth 16.00Gbps, Throughput 1.15Gbps (8.35%)
3: 4-> 6 10:00:00:27:f8:ff:1e:20 12 deskew 15 MASTER
5-> 7 10:00:00:27:f8:ff:1e:20 12 deskew 15
Tx: Bandwidth 16.00Gbps, Throughput 2.56Gbps (18.62%)
Rx: Bandwidth 16.00Gbps, Throughput 261.54Mbps (1.90%)
Tx+Rx: Bandwidth 32.00Gbps, Throughput 2.82Gbps (10.26%)
В данном примере у нас 3 транка. Один состоит из двух линков и ещё 2 транка по одному линку. Хотелось бы объяснить почему первые 2 линка не собрались в один транк. Как я уже говорил выше — обязательным условием, что бы собрать транк должна являться одинаковая конфигурация портов. В данном случае это не так, настройки портов специально сделаны не верно, чтобы можно было продемонстрировать, что и такой вариант возможен. Из примера видно, что в случае транка из двух линков, Master линков является только один из них.
trunkdebug с указанием портов, которые должны собираться в транк, подскажет причины, почему этого не произошло
switch:admin> trunkdebug 0 1
port 0 and 1 can’t trunk due to one of the following reasons:
ports are not same speed or valid speed
ports are not same long distance mode
local or remote ports are not in same port group
difference between links length is greater than allowed
Посмотреть существующие ISL линки можно при помощи islshow
switch:admin> islshow
1: 0-> 0 10:00:00:27:f8:de:d2:7c 10 IBM_2498_24G_FS sp: 8.000G bw: 8.000G TRUNK CR_RECOV
2: 1-> 1 10:00:00:27:f8:de:d2:7c 10 IBM_2498_24G_FS sp: 8.000G bw: 8.000G TRUNK CR_RECOV
3: 4-> 6 10:00:00:27:f8:ff:1e:20 12 IBM_2498_24G_FS sp: 8.000G bw: 16.000G TRUNK CR_RECOV
На этом на сегодня всё. Мы ещё будем говорить о роутинге в 10-й части этого повествования, но пока на уровне одной фабрики этих знаний нам должно быть достаточно. Если у вас остались вопросы или что то не совсем понятно — приглашаю в комментарии.
Большое спасибо за данный цикл, мне как начинающему он очень пригодится!
Запутался со схемой… получается Port A — это свитч c Port F, а Port B — это узел с Port N.
Тогда если N-порт высылает LR (Link Reset) в сторону F-порта, на что последний отвечает сообщением LRR (LR Response) — то на схеме тогда высылать LR должен Port B, а у Вас на схеме Port A
Добрый день. да, вы правы. К сожалению, уже не помню, откуда именно брал данную схему