NetApp для самых маленьких. Часть 1

Порой ко мне обращаются за инструкцией по настройке системы под управлением ONTAP, но большая официальная документация подходит не всем. Порой требования бизнеса требуют подхода «раз-два и в продакшн». Поэтому стоит задача быстро запустить систему, а потом уже вдумчиво читать документацию, ходить на курсы и нарабатывать опыт и знания.
Конечно же я, да как и многие другие специалисты, которым приходится подчиняться таким условиям, не рады данному подходу. Поэтому я не просто напишу инструкцию — как быстро настроить систему и запустить в работу, но и каждый пункт снабжу подборкой ссылок на документацию, чтобы каждый желающий мог потом данную тему изучить более подробно, ну или тот, кто просто хочет понимать по шагам что необходимо делать, сразу ознакомился с подборкой документации. Также постараюсь по максимуму приложить бесплатных роликов от Neil Anderson, которые он выкладывает на своём YouTube канале, которые в свою очередь являются усечёнными версиями из его, на мой взгляд лучшего в принципе, курса по NetApp — NetApp ONTAP 9 Storage Complete, который я очень рекомендую. Во-первых, он намного больше и глубже, чем то, что даётся в рамках вендорского курса по NetApp. Общая продолжительность роликов в его курсе — 43.5 часа! Если кто-то бывал на вендорских курсах, то знает, что в большинстве случаев они длятся неделю, за день занятие длится около 7 часов — из этих 7 часов стоит сразу вычесть часа 2 на все перерывы, а также ещё часа 2 на все лабораторки. В итоге получается, что вам теории прочитают намного меньше, чем даёт Neil. Во-вторых, стоимость курса всего 19799 (по состоянию на 11 мая 2020 года), что просто в 10 раз дешевле, чем официальный курс. А я напоминаю, что для сдачи сертификационного экзамена NetApp нет требования к обязательному прохождению официального курса.
За отправную точку возьмём систему под управлением ONTAP, неважно FAS или AFF. Первоначально вам необходимо установить её в стойку. Первое, что вам необходимо сделать после установки — подключение всех необходимых портов. В зависимости от модели — этот процесс и сами порты будут отличаться. В комплекте с вашей системой должен идти красочный постер «Installation and Setup Instructions” в котором подписаны все порты и указано, каким образом подключаются полки. Если вдруг постера по какой-то причине в комплекте нет, то его всегда можно найти в AFF and FAS System Documentation Center, где для каждой из систем есть раздел Installation and setup PDF poster. Но не торопитесь включать контроллер сразу после коммутации. В постере, к сожалению, не указано, что первыми необходимо включать именно дисковые полки (если у вас есть дополнительные полки под накопители) и первое, что необходимо сделать после их включения — установить уникальный Shelf ID для каждой из полок. Changing the disk shelf ID. А вот по этой ссылке рекомендую ознакомиться с Shelf numbering best practice. И только после этого можно включать контроллер. Если же по какой-то причине он всё же оказался у вас включен, то его необходимо перезагрузить, чтобы он увидел полки под новыми ID.
Первоначальное конфигурирование.
И так, мы запустили систему. Осталось получить к ней доступ. Дело в том, что массивы NetApp идут без преднастроенных дефолтных адресов на контроллерах и вам придётся подключаться к массиву через консольный кабель чтобы их настроить.
Я буду описывать процесс настройки через консольный кабель, на мой взгляд это лучше покажет весь процесс. Но стоит отметить, что есть и другие варианты.
- Настроить менеджмент только на одной ноде, а потом уже через web-интерфейс настроить второй контроллер и собрать кластер
- Метод с одновременным подключением вашей рабочей станции к консольному порту и менеджмент коммутатору — Completing system setup and configuration if network discovery is not enabled, но я сам этим методом никогда не пользовался, т.к. медные коммутаторы у меня далеко не всегда стоят рядом с самим массивом и нужно лезть куда то в соседнюю стойку, настраивать интерфейс на ноутбуке и т.д. На мой взгляд настройка через консольный порт самая быстрая и удобная.
Подключившись через консоль к первому контроллеру, вы увидите вот такое сообщение
Welcome to the cluster setup wizard.
You can enter the following commands at any time:
«help» or «?» — if you want to have a question clarified,
«back» — if you want to change previously answered questions, and
«exit» or «quit» — if you want to quit the cluster setup wizard.
Any changes you made before quitting will be saved.
You can return to cluster setup at any time by typing «cluster setup».
To accept a default or omit a question, do not enter a value.
This system will send event messages and periodic reports to NetApp Technical
Support. To disable this feature, enter
autosupport modify -support disable
within 24 hours.
Enabling AutoSupport can significantly speed problem determination and
resolution should a problem occur on your system.
For further information on AutoSupport, see:
http://support.netapp.com/autosupport/
Type yes to confirm and continue {yes}:
После набора «yes» вам будет предложено настроить IP адрес на этом контроллере
Enter the node management interface port [e0M]:
Enter the node management interface IP address: 10.10.0.10
Enter the node management interface netmask: 255.255.255.0
Enter the node management interface default gateway: 10.10.0.1
A node management interface on port e0M with IP address 10.10.0.10 has been created.
Далее события могут развиваться двумя путями — вы продолжаете создание кластера между контроллерами также через консоль, либо подключаетесь ко второму контроллеру, аналогичным образом настраиваете менеджмент IP на нём и уже через браузер по сети подключаетесь на один из контроллеров и конфигурируете кластер при помощи Guided Setup.

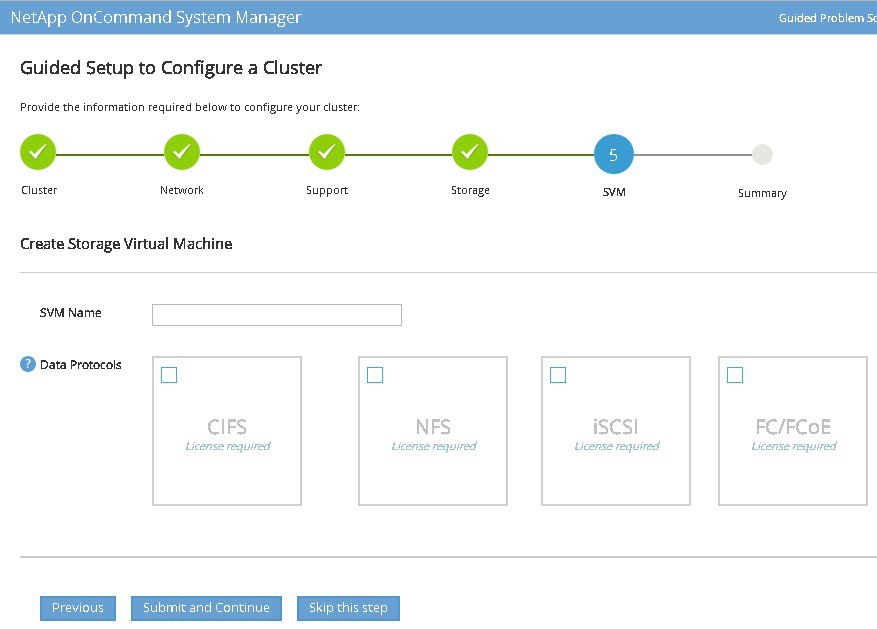
На мой взгляд, если вы делаете это первый раз, то Guided Setup будет более предпочтителен ввиду наличия подсказок и необходимости указания всех обязательных параметров при конфигурировании. Естественно (как и всё в системах ONTAP) это можно сделать и через консоль, но в этом случае вы должны быть более подготовленным и знать, что же именно необходимо настраивать. Но т.к. я претендую на некую пошаговую инструкцию по настройке и описываю всё, что необходимо настроить в первую очередь, то мы пойдём по пути ручной настройки. Вообще системы на ONTAP мне больше нравится администрировать через консоль, поэтому и настройку в этом гайде мы так же будем выполнять через консоль. Это и удобнее и быстрее, чем через WUI. Да, ONTAP 9.7 получил новый интерфейс и теперь через него очень просто собрать агрегаты, создать луны, инициаторов и раздать доступ. Это можно сделать из одного мастера буквально за пару минут. Но на мой взгляд, если вы только знакомитесь с системами на ONTAP и воспользуетесь этим мастером, потом у вас возникнет намного больше вопросов по всем тем сущностям, которые он создавал в вашей системе и без детального понимания — что из этого для чего нужно, первые же проблемы с системой могут стать для вас очень болезненными. Поэтому делать всё будем из консоли и стараться понять — что и для чего в этой системе делается и как работает. А подборка ссылок на документацию и полезные статьи в конце каждой секции поможет вам глубже познакомиться со всеми технологиями, используемыми в системах ONTAP.
Как я уже говорил, прежде всего создаётся кластер из двух контроллеров в вашей системе. Если вы имели дело с СХД других производителей, то знаете, что там такой необходимости нет. Контроллеры уже знают друг о друге и работают в паре. Но дело в том, что кластер систем на базе ONTAP может содержать более двух контроллеров, которые соединяются при помощи внешних Cluster свичей. Соответственно настройки сети на них могут варьироваться.
Мы остановились на том, что настроили менеджмент адрес на первом контроллере и далее он предлагает нам создать кластер.
Do you want to create a new cluster or join an existing cluster? {create, join}:
так как мы пока настраиваем только первый контроллер и кластер ещё не создавали, набираем команду — create
Следующим шагом система спрашивает нас будет ли это однонодовый кластер (да, такие варианты работы тоже поддерживаются)
Do you intend for this node to be used as a single node cluster? {yes, no} [no]:
На что мы отвечаем — no, т.к. у нас есть второй контроллер, который мы позже добавим в кластер.
Далее система нам предложит существующие с завода настройки для портов интеркластера
Existing cluster interface configuration found:
Port MTU IP Netmask
e0a 9000 169.254.18.124 255.255.0.0
e0b 9000 169.254.184.44 255.255.0.0
Do you want to use this configuration? {yes, no} [yes]:
Если у нас нет каких-то задумок относительно IP адресации для интеркластера, то с данными настройками можно согласиться и записать предложенные нам адреса, т.к. их необходимо будет указать на втором контроллере, при присоединении его к созданному кластеру. Либо, если адресация вас по какой-то причине не устраивает, отказаться и задать параметры вручную.
Задаём имя кластера
Enter the cluster name: clu_1
После этого произойдёт непосредственное создание кластера и запуск необходимых для его работы сервисов
Creating cluster cluster_A
Starting cluster support services …
Cluster clu_1 has been created.
Следующий этап — добавление приобретённых для системы лицензий
Enter an additional license key []:
Ключи задаются просто через запятую.
И последнее, что нам потребуется на данном этапе, задать настройки для кластерного интерфейса управления. Помимо адресов самих нод, у системы так же будет общий, кластерный адрес для управления массивом, который будет доступен даже в случае выхода из строя одного из контроллеров, т.к. виртуальный менеджмент интерфейс может переезжать с одного контроллера на другой. Также настройки дополняются указанием NTP и DNS.
Enter the cluster management interface port [e0M]:
Enter the cluster management interface IP address: 10.10.0.12
Enter the cluster management interface netmask: 255.255.252.0
Enter the cluster management interface default gateway: 10.10.0.1
A cluster management interface on port e3a with IP address 10.10.0.12 has been created. You can use this address to connect to and manage the cluster.
Enter the DNS domain names: lab.netapp.com
Enter the name server IP addresses: 10.10.0.5
DNS lookup for the admin Vserver will use the lab.netapp.com domain.
Теперь настало время подключиться ко второму нашему контроллеру. Нам необходимо также настроить на нём менеджмент адрес.
Enter the node management interface port [e0M]:
Enter the node management interface IP address: 10.10.0.11
Enter the node management interface netmask: 255.255.255.0
Enter the node management interface default gateway: 10.10.0.1
A node management interface on port e0M with IP address 10.10.0.11 has been created.
А на следующем шаге
Do you want to create a new cluster or join an existing cluster? {create, join}:
Выбрать уже не create, т.к. кластер мы создали уже при помощи первого контроллера, а выбрать join.
После этого потребуется указать IP адреса кластерного интерконнекта, которые, как я говорил ранее, необходимо записать. После этого ноды смогут друг друга увидеть и второй контроллер добавится в кластер.
Теперь мы можем подключиться по нашему кластерному адресу 10.10.0.12 и проверить, что наш кластер работает корректно.
Необходимо убедиться, что оба контроллера работают в high-availability режиме.
storage failover show -fields mode
Убедиться, что используется 4 порта (по 2 с каждого контроллера) для кластерного интерконнекта
network port show -role cluster
Если всё так, то первоначальная настройка завершена.
Полезные материалы по данной секции:
NetApp Bootup Process Tutorial
High-availability pairs
Cluster storage
Кластеризация СХД NetApp используя подручные свичи
Зонинг для кластерного хранилища в картинках
NetApp Cluster, Management, Data and HA Networks Tutorial
NetApp High Availability
Service Processor
На системах под управлением ONTAP на каждом контроллере есть SP или BMC для удалённого доступа к контроллерам. Примерно тоже самое, что удалённый менеджмент для физических серверов. Это позволит вам подключиться к контроллеру, даже если на нём не запущена система ONTAP. Это помогает, как при проблемах с оборудованием (например, контроллер по какой-то причине не может загрузиться), так и для некоторых действий, которые требуют входа в Boot меню (например, переинициализация системы с нуля). Для SP/BMC не используется выделенного порта, используется тот же e0M. Настраивается по отдельности на каждом из контроллеров:
system node service-processor network modify -node clu_1-01 -address-type IPv4 -enable true -ip-address 10.10.0.13 -netmask 255.255.255.0 -gateway 10.10.0.1
system node service-processor network modify -node clu_1-02 -address-type IPv4 -enable true -ip-address 10.10.0.14 -netmask 255.255.255.0 -gateway 10.10.0.1
Доступ до SP осуществляется по средствам протокола SSH.
Полезные материалы по данной секции:
NetApp Service Processor SP and BMC Tutorial
Aggregates
Наша система запустилась и нам уже хочется поскорее отдать дисковые ресурсы нашим серверам, но не всё так просто и быстро, т.к. есть ряд подготовительных мероприятий, которые мы должны выполнить. И так, у нас есть набор дисков, которые мы планируем использовать в нашей системе. И прежде всего, нам необходимо создать агрегаты для данных. Агрегат — это по факту ещё одна виртуальная сущность, которая объединяет под собой обычные RAID-группы. ONTAP поддерживает 3 типа RAID: raid_tec, raid_dp, raid4.
clu_1::> aggr show
Aggregate Size Available Used% State #Vols Nodes RAID Status
——— ——— ——— —— ——- —— —————- ————
aggr0_clu_1_01
855MB 41.52MB 95% online 1 clu_1-01 raid_dp,
normal
aggr0_clu_1_02
855MB 42.13MB 95% online 1 clu_1-02 raid_dp,
normal
2 entries were displayed.
На моей свежесозданной (а я использую в данном случае NetApp Simulator) уже есть 2 агрегата. Их система создала самостоятельно при инициализации (первом запуске). Это так называемые рутовые агрегаты, которые используются для нужд самой системы (с ними мы чуть позже ещё будем сталкиваться).
Если мы рассмотрим один из агрегатов внимательнее
clu_1::> aggr show -aggregate aggr0_clu_1_01
Number Of Disks: 4
то увидим, что он состоит из 4 накопителей (вообще по умолчанию из 3, но я уже расширил свои агрегаты из-за слишком малого количества свободного места на них). Это не совсем верно для систем FAS/AFF, но нормально для NetApp Simulator. Дело в том, что ещё несколько лет назад компания NetApp представила технологию Advanced Drive Partitioning (ADP). Когда-то давно для рутовых агрегатов использовались выделенные диски. Было это, скажем так, не очень эффективно с точки зрения полезной ёмкости системы. Давай посчитаем: мы купили систему с 12 дисками. 6 дисков (по 3 на каждый контроллер) нам необходимо было выделить для рутовых агрегатов. Пару дисков выделить под spare, в итоге у нас остаётся 4 диска. Мы собираем агрегат в raid_dp с двумя дисками чётности и в итоге у нас под данные остаётся всего-навсего объём только 2 дисков. И это я ещё упускаю тот факт, что неплохо бы балансировать нагрузку между контроллерами, т.е. агрегата для данных должно быть 2. В итоге из 12 дисков у нас полезный объём составлял размер 2 дисков, т.е. всего около 17%. Это очень низкий показатель. Конечно, он рос с увеличением количества дисков в системе, но тем не менее. Компания NetApp также понимала, что это неэффективно и разработала технологию ADP (Root-Data (RD)), которая стала стандартом для всех систем после выхода ONTAP 8.3. Она не требует отдельных лицензий или дополнительных настроек, всё работает уже при старте системы. Что же она из себя представляет? Теперь нам не требуются отдельные диски для рутовых агрегатов. Система самостоятельно создаёт из накопителя «контейнер» и делит его на 2 партиции, маленькая партиция используется для рутового агрегата, большая же отдаётся под данные. Соответственно полезное количество дисков у нас не меняется, а только уменьшается их объём.

А для SSD накопителей (как на AFF, так и FAS системах) используется ADPv2 (ADPv2 — Root-Data-Data (RD2)
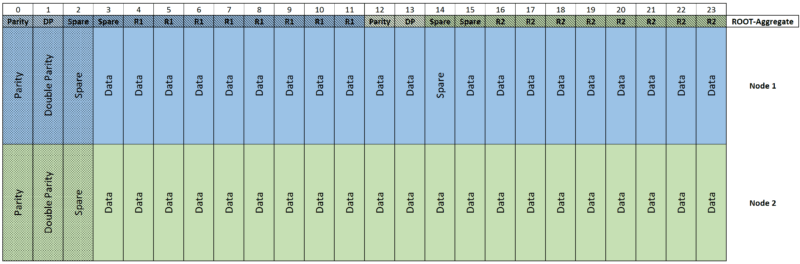
Теперь на накопителе у нас не 2 партиции, а 3 (одна рутовая и 2 под данные) и имеем возможность разные партиции под данные с одного накопителя отдать разным контроллерам. Но самое главное — одни и те же накопители мы можем использовать в качестве spare и дисков чётности, что опять-таки уменьшает накладные расходы, когда мы должны их выделить в каждом агрегате на каждом из контроллеров.
AFF системы поддерживают ADPv2 на не более чем 48 накопителях (кроме AFF A220/A800, на которых вы увидите несколько партиций только на внутренних 24 накопителях, т.к. эти системы имеют внутренние накопители и на заводе инициализируется без дополнительных полок). Что же касается FAS систем, то у них максимальное количество накопителей в ADP — 24. Всё что больше этого количества будет добавляться уже целыми накопителями в группы.
И ещё немного ограничений — ADP не поддерживается для FAS в конфигурации MetroCluster (но поддерживается на AFF в MetroCluster IP)
Стоит отметить и минусы ADP:
- Сбой одного носителя диска влияет на работу нескольких RAID групп, агрегатов и зачастую обоих узлов в HA-паре
- Пиковые нагрузки на системном агрегате могут оказать влияние на производительность разделов данных
Самая главная рекомендация — не нужно лишний раз играться с это технологией. Как система пришла инициализированной с завода — так лучше и оставить, а остальные накопители добавлять уже целыми партициями в систему.
Теперь вернёмся к моему тестовому стенду и посмотрим на диски.
clu_1::> disk show
Usable Disk Container Container
Disk Size Shelf Bay Type Type Name Owner
—————- ———- —— — ——- ———— ——— ———
NET-1.1 — — 16 FCAL unassigned — —
NET-1.2 — — 17 FCAL unassigned — —
NET-1.3 — — 18 FCAL unassigned — —
NET-1.4 — — 19 FCAL unassigned — —
NET-1.5 — — 20 FCAL unassigned — —
NET-1.6 — — 21 FCAL unassigned — —
NET-1.7 — — 22 FCAL unassigned — —
NET-1.8 — — 24 FCAL unassigned — —
NET-1.9 — — 25 FCAL unassigned — —
NET-1.10 — — 26 FCAL unassigned — —
NET-1.11 — — 27 FCAL unassigned — —
NET-1.12 — — 28 FCAL unassigned — —
NET-1.13 — — 29 FCAL unassigned — —
NET-1.14 1020MB — 16 FCAL aggregate aggr0_clu_1_01
clu_1-01
NET-1.15 1020MB — 17 FCAL aggregate aggr0_clu_1_01
clu_1-01
NET-1.16 1020MB — 18 FCAL aggregate aggr0_clu_1_01
clu_1-01
NET-1.17 1020MB — 19 FCAL aggregate aggr0_clu_1_01
clu_1-01
NET-1.18 1020MB — 20 FCAL spare Pool0 clu_1-01
NET-1.19 1020MB — 21 FCAL spare Pool0 clu_1-01
NET-1.20 1020MB — 22 FCAL spare Pool0 clu_1-01
NET-1.21 1020MB — 24 FCAL spare Pool0 clu_1-01
NET-1.22 1020MB — 25 FCAL spare Pool0 clu_1-01
NET-1.23 1020MB — 26 FCAL spare Pool0 clu_1-01
NET-1.24 1020MB — 27 FCAL spare Pool0 clu_1-01
NET-1.25 1020MB — 28 FCAL spare Pool0 clu_1-01
NET-1.26 1020MB — 29 FCAL spare Pool0 clu_1-01
NET-1.27 1020MB — 32 FCAL spare Pool0 clu_1-01
NET-1.28 — — 32 FCAL unassigned — —
NET-1.29 — — 16 FCAL unassigned — —
NET-1.30 — — 17 FCAL unassigned — —
NET-1.31 — — 18 FCAL unassigned — —
NET-1.32 — — 19 FCAL unassigned — —
NET-1.33 — — 20 FCAL unassigned — —
NET-1.34 — — 21 FCAL unassigned — —
NET-1.35 — — 22 FCAL unassigned — —
NET-1.36 — — 24 FCAL unassigned — —
NET-1.37 — — 25 FCAL unassigned — —
NET-1.38 — — 26 FCAL unassigned — —
NET-1.39 — — 27 FCAL unassigned — —
NET-1.40 — — 28 FCAL unassigned — —
NET-1.41 1020MB — 16 FCAL aggregate aggr0_clu_1_02
clu_1-02
NET-1.42 1020MB — 17 FCAL aggregate aggr0_clu_1_02
clu_1-02
NET-1.43 1020MB — 18 FCAL aggregate aggr0_clu_1_02
clu_1-02
NET-1.44 1020MB — 19 FCAL aggregate aggr0_clu_1_02
clu_1-02
NET-1.45 1020MB — 20 FCAL spare Pool0 clu_1-02
NET-1.46 1020MB — 21 FCAL spare Pool0 clu_1-02
NET-1.47 1020MB — 22 FCAL spare Pool0 clu_1-02
NET-1.48 1020MB — 24 FCAL spare Pool0 clu_1-02
NET-1.49 — — 29 FCAL unassigned — —
NET-1.50 — — 32 FCAL unassigned — —
NET-1.51 1020MB — 25 FCAL spare Pool0 clu_1-02
NET-1.52 1020MB — 26 FCAL spare Pool0 clu_1-02
NET-1.53 1020MB — 27 FCAL spare Pool0 clu_1-02
NET-1.54 1020MB — 28 FCAL spare Pool0 clu_1-02
NET-1.55 1020MB — 29 FCAL spare Pool0 clu_1-02
NET-1.56 1020MB — 32 FCAL spare Pool0 clu_1-02
56 entries were displayed.
Можно сделать следующие выводы:
- В нашей системе всего 56 накопителей
- У нас есть 8 накопителей, которые принадлежат clu_1-01 или clu_1-02 и состоят в aggr0_clu_1_01 или aggr0_clu_1_02 (это как раз наши рутовые агрегаты)
- Часть накопителей имеют своего владельца в виде clu_1-01 или clu_1-02, находятся в Pool0 и имеют тип spare (это диски, которые входят в ту же группу, что и диски для рутовых агрегатов, но они свободны для создания агрегатов для данных)
- Куча дисков в состоянии unassigned, которые не имеют владельцев
И теперь хочу обратить ваше внимание на важный момент — каждый диск в системе должен иметь в качестве своего владельца один из контроллеров, иначе он будет болтаться там просто так. Обычно диски делятся поровну между контроллерами для балансировки нагрузки. Но иногда, умышленно, бывают и перекосы, если у нас есть небольшое количество разных типов дисков. Один агрегат может быть на SSD отдан первому контроллеру, а ещё 2 небольших агрегата на SAS и NL-SAS дисках отданы второму контроллеру. Основная проблема в необходимости делить диски между контроллерами — невозможно создать из них один большой агрегат, т.е. увеличиваются наши накладные расходы на RAID и spare для каждого из контроллеров. По этой причине нужно очень внимательно отнестись к планированию.
Но в моём случае у меня 56 «виртуальных» накопителя по 1Гб каждый, т.к. это NetApp Simulator и я просто поделю их поровну между контроллерами. И это единственная операция, которую на мой взгляд удобнее делать именно из веб интерфейса, нежели из консоли. Но делать это (может быть это только моё личное мнение) удобно именно в старом system manager, ибо system manager 9.7 совершенно неудобен, да ещё и довольно кривой.
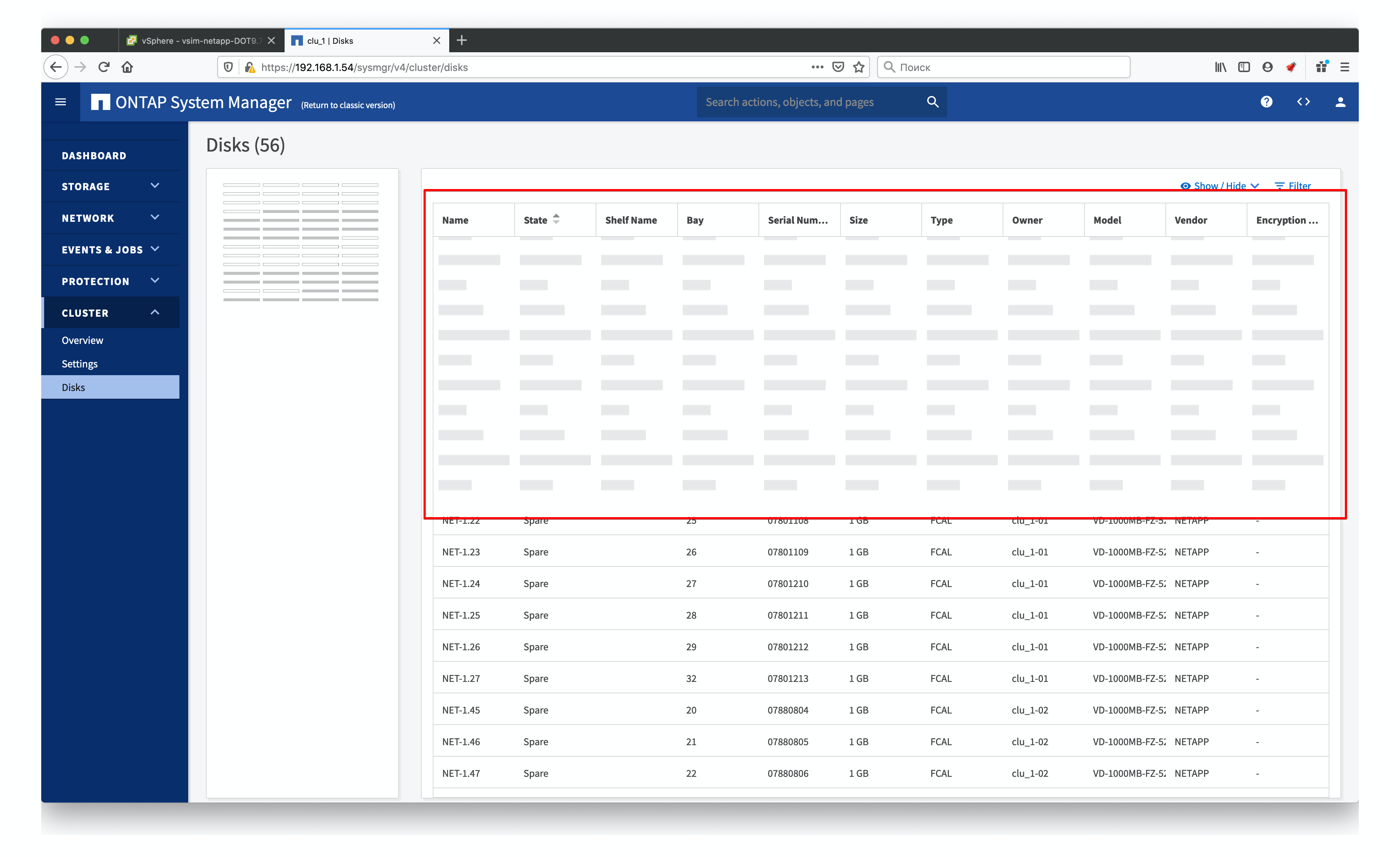
При этом в старой версии мы просто заходим в раздел Disks, щёлкаем по заголовку столбца Container type, оставляем там только unassigned и получаем список дисков, которые нам нужно привязать. Выделяем первую половину дисков и привязываем к первому контроллеру, потом то же самое делаем со второй половиной.
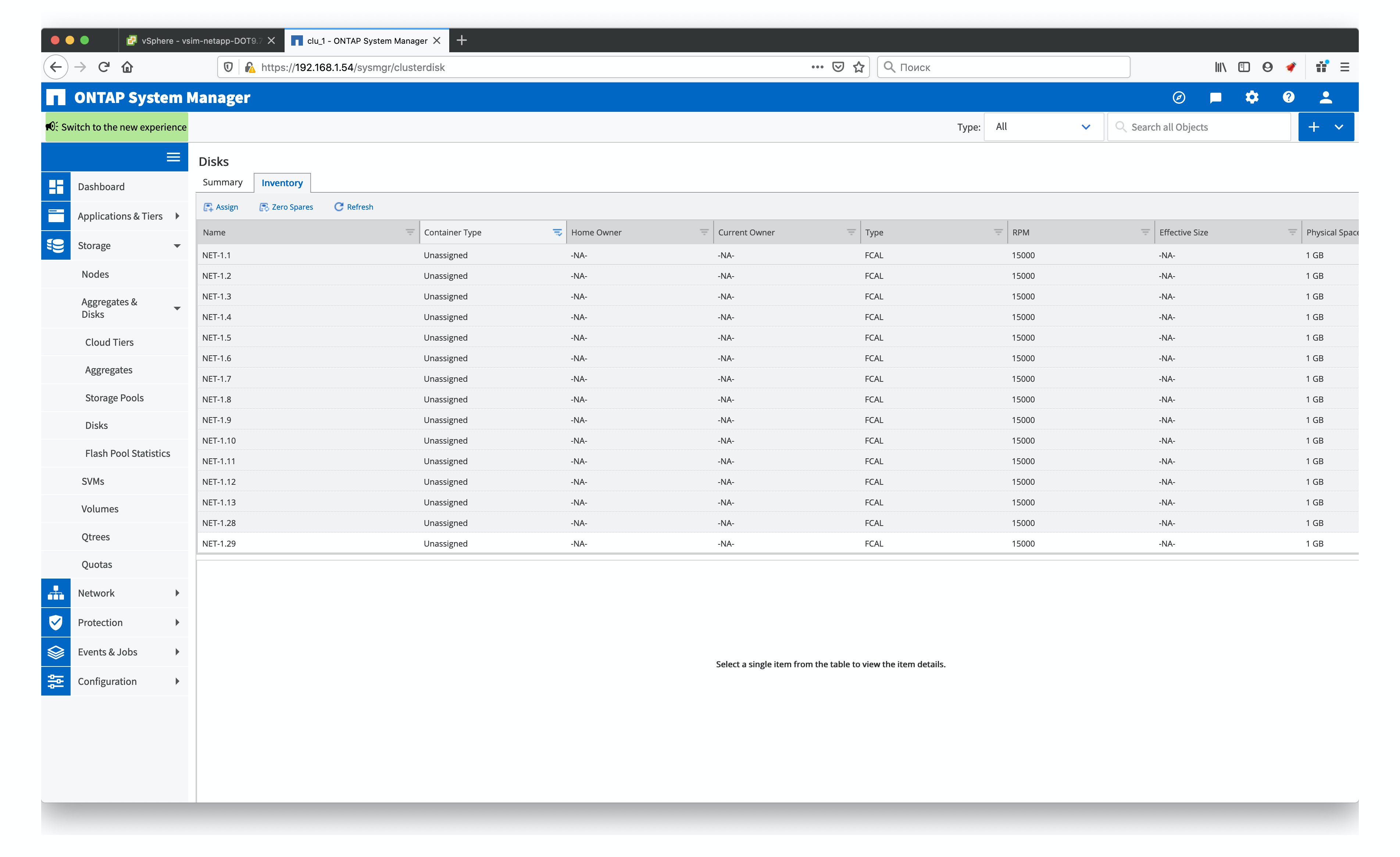
Весь процесс занимает буквально пару минут. При этом из консоли вам бы пришлось вручную перечислять ID тех дисков, которые вы хотите привязать или воспользоваться опцией -all, которая бы привязала все доступные диски к одной из нод. Этим можно было бы воспользоваться после того, как были указаны диски, которые мы бы привязали к первой ноде, а ко второй уже все оставшиеся в автоматическом режиме. Но это всё равно заняло бы больше времени.
Теперь у каждого контроллера у нас есть по 24 свободных диска (помимо тех 4, которые у нас собраны в рутовый агрегат). Создадим на них по одному агрегату для данных
clu_1::> aggr create -aggregate aggr1_01 -diskcount 23 -node clu_1-01
clu_1::> aggr create -aggregate aggr1_02 -diskcount 23 -node clu_1-02
Для новичков имеет смысл использовать дополнительную опцию -simulate true, которая позволит посмотреть, что именно система создаст на основе наших команд и если результат именно тот, что мы хотим, можно запустить уже второй без неё и непосредственно создать агрегат.
Как мы можем видеть по выводу консоли, при создании агрегата создаётся и несколько RAID-групп
RAID Group rg0, 16 disks (block checksum, raid_dp)
Usable Physical
Position Disk Type Size Size
———- ————————- ———- ——— ———
dparity NET-1.29 FCAL — —
parity NET-1.45 FCAL — —
data NET-1.30 FCAL 1000MB 1.00GB
data NET-1.46 FCAL 1000MB 1.00GB
data NET-1.31 FCAL 1000MB 1.00GB
data NET-1.47 FCAL 1000MB 1.00GB
data NET-1.32 FCAL 1000MB 1.00GB
data NET-1.48 FCAL 1000MB 1.00GB
data NET-1.33 FCAL 1000MB 1.00GB
data NET-1.51 FCAL 1000MB 1.00GB
data NET-1.34 FCAL 1000MB 1.00GB
data NET-1.52 FCAL 1000MB 1.00GB
data NET-1.35 FCAL 1000MB 1.00GB
data NET-1.53 FCAL 1000MB 1.00GB
data NET-1.36 FCAL 1000MB 1.00GB
data NET-1.54 FCAL 1000MB 1.00GB
RAID Group rg1, 7 disks (block checksum, raid_dp)
Usable Physical
Position Disk Type Size Size
———- ————————- ———- ——— ———
dparity NET-1.37 FCAL — —
parity NET-1.55 FCAL — —
data NET-1.38 FCAL 1000MB 1.00GB
data NET-1.56 FCAL 1000MB 1.00GB
data NET-1.39 FCAL 1000MB 1.00GB
data NET-1.40 FCAL 1000MB 1.00GB
data NET-1.49 FCAL 1000MB 1.00GB
Размер RAID-группы также можно настроить. Дефолтный размер — 16 дисков. Как мы видим — вторая рейд группа меньше по количеству дисков. Соответственно при добавлении новых дисков в этот агрегат — эта группа будет увеличиваться и при достижении также 16 дисков произойдёт создание уже следующей группы.
При создании агрегатов нужно придерживаться рекомендаций вендора по размеру рейд-группы в зависимости от типа накопителя и используемого уровня RAID — Storage limits.
Как я уже говорил — агрегат состоит из нескольких рейд-групп. Не всегда у нас такое количество накопителей, которое мы можем равномерно распределить по рейд группам. Поэтому есть рекомендация делать размер групп таким, что бы последняя группа была максимально близка в размеру остальных групп.
Например — у нас есть 23 накопителя под данные, как в моём примере выше. При создании, размер рейд-группы был оставлен по умолчанию — 16 накопителей. В итоге в агрегате у нас 2 группы, и вторая больше чем на 50% меньше, чем первая. В случае с HDD дисками вы точно получите проблемы производительности на данном агрегате. В данном случае стоило указать размер группы в 12 (при помощи параметра -maxraidsize 12) накопителей и получить последнюю группу близкой по размеру к основной. Тогда баланс производительности между группами будет сохранён.
Уменьшать аггрегат, просто убрав из него диски — невозможно. Единственный способ это сделать, сменить тип рейда с TEC на DP и/или DP на RAID-4, чем мы можем высвободить 1-2 накопителя из группы, за счёт уменьшения уровня защиты.
Я создаю агрегаты из 23 дисков, чтобы у каждого из контроллеров осталось по одному spare диску. Также каждый из агрегатов, я как и диски привязываю к контроллерам. Это не значит, что в случае выхода одного из контроллеров мы потеряем весь наш агрегат, нет, у него автоматически сменится владелец и всеми операциями будет руководить второй контроллер. Скажем так, это «дефолтный» владелец, который обслуживает данный агрегат при нормальной работе системы.
Теперь можем посмотреть на все 4 наших агрегата
clu_1::> aggr show
Aggregate Size Available Used% State #Vols Nodes RAID Status
——— ——— ——— —— ——- —— —————- ————
aggr0_clu_1_01
1.67GB 897.1MB 48% online 1 clu_1-01 raid_dp,
normal
aggr0_clu_1_02
1.67GB 895.1MB 48% online 1 clu_1-02 raid_dp,
normal
aggr1_01 16.70GB 16.70GB 0% online 0 clu_1-01 raid_dp,
normal
aggr1_02 16.70GB 16.70GB 0% online 0 clu_1-02 raid_dp,
normal
4 entries were displayed.
и удостовериться, что у нас действительно есть 2 spare диска
clu_1::> aggr show-spare-disks
Original Owner: clu_1-02
Pool0
Spare Pool
Usable Physical
Disk Type Class RPM Checksum Size Size Status
—————- —— ———— —— ————— ——— ——— ———
NET-1.28 FCAL performance 15000 block 1020MB 1.00GB zeroed
NET-1.50 FCAL performance 15000 block 1020MB 1.00GB zeroed
2 entries were displayed.
Полезные материалы по данной секции:
Data ONTAP 8.3 ADP: Root-Data Partitioning
Root-data partitioning
ADP(v1) and ADPv2 in a nutshell, it’s delicious!
Организация дискового пространства у NetApp (вебинар компании Netwell)
Мистическая тема эффективности хранения
RAID Groups and Aggregates on NetApp ONTAP
Если вы планируете использовать только FC подключение, то эту секцию можно пропустить и перейти сразу к созданию SVM, но если вас интересует протокол iSCSI или файловый доступ, то следует помнить, что существует 3 связанных вещи, которые вам понадобятся для этого:
- IPspace
- Broadcast domains
- VLAN’ы
VLANs, broadcast domain, ipspace
И так, ipspace необходимы нам для обеспечения мультитенантности на нашей СХД. Может так произойти, что IP адресация ваших клиентов будет пересекаться, и для обепечения их доступа к SVM и необходимы ipspace’ы. Для каждого из них поддерживается отдельная таблица маршрутизации. При этом ipspace’ы между собой не пересекаются. Ipspace’ы связаны с широковещательными доменами, задача которых сводится к установке размера MTU на портах.
На самом деле, на нашей свеже-развёрнутой системе уже имеются стандартные ipspace’ы:
clu_1::> network ipspace show
IPspace Vserver List Broadcast Domains
——————- —————————— —————————-
Cluster
Cluster Cluster
Default
clu_1 Default
2 entries were displayed.
Если мы рассмотрим в подробностях один из наших ipspace’ов, то увидим, что он привязывается к портам и VServer’ы (но о нём позже)
clu_1::> network ipspace show -ipspace Cluster
IPspace name: Cluster
Ports: clu_1-01:e0a, clu_1-01:e0b, clu_1-02:e0a, clu_1-02:e0b
Broadcast Domains: Cluster
Vservers: Cluster
При создании нового ipspace’а нет необходимости указывать дополнительные параметры, помимо его названия
clu_1::> network ipspace create -ipspace korphome
Так же у нас есть и широковещательные домены, которые связаны с дефолтными ipspace’ами
clu_1::> network port broadcast-domain show
IPspace Broadcast Update
Name Domain Name MTU Port List Status Details
——- ———— —— —————————— —————
Cluster Cluster 9000
clu_1-01:e0a complete
clu_1-01:e0b complete
clu_1-02:e0a complete
clu_1-02:e0b complete
Default Default 1500
clu_1-01:e0c complete
clu_1-01:e0d complete
clu_1-01:e0e complete
clu_1-02:e0c complete
clu_1-02:e0d complete
clu_1-02:e0e complete
2 entries were displayed.
А теперь создадим для нашей сети
clu_1::> network port broadcast-domain create -broadcast-domain korphome -mtu 9000 -ipspace korphome
Как мы видим в выводе команды network port broadcast-domain show, все имеющиеся у нас порты принадлежат дефолтному домену. Нам нужно переопределить необходимые нам порты в созданный домен.
Удаляем наши порты из дефолтного домена
clu_1::> network port broadcast-domain remove-ports -broadcast-domain Default -ports clu_1-01:e0e, clu_1-02:e0e
Добавляем порты в наш домен
clu_1::> network port broadcast-domain add-ports -broadcast-domain korphome -ipspace korphome -ports clu_1-01:e0e, clu_1-02:e0e
Что касается портов. Конечно же в вашей конфигурации они могут быть другими и их будет другое количество. Это лишь пример того, что вам необходимо сделать с теми портами, которые вы планируете использовать для подключения.
Теперь мы можем удостовериться, что сделали всё верно
clu_1::> network port broadcast-domain show
IPspace Broadcast Update
Name Domain Name MTU Port List Status Details
——- ———— —— —————————— —————
korphome
korphome 9000
clu_1-02:e0e complete
clu_1-01:e0e complete
Оба наших порта относятся к IPspace’у korphome, к домену korphome и имеют MTU 9000.
Полезные материалы по данной секции:
How VLANs work
NetApp VLANs Tutorial Video
NetApp Broadcast Domains and Failover Groups
NetApp networking — IPspaces
NetApp Interface Groups Configuration
Изначально я планировал написать это одной большой статьёй. Но посмотрев на уже получившийся объём, да и скорость написания, решил его всё-таки поделить на несколько частей. И это конец первой части. Предварительные настройки мы все выполнили и в следующей части перейдём уже к созданию SVM и настройке протоколов доступа к нашим лунам и шарам.
Так же хочу выразить отдельную благодарность Алексею Сарычеву, за помощь в подготовке этого материала.
Оглавление:
NetApp для самых маленьких. Часть 1
NetApp для самых маленьких. Часть 2
NetApp для самых маленьких. Часть 3