Veeam Direct SAN restore и скорость
В недавней своей статье я говорил о том, как хорошо иметь интеграцию ПО для РК и продуктивной СХД, насколько это снижает нагрузку на продуктив и увеличивает скорость. Сегодня же поговорим о восстановлении виртуальных машин Direct SAN, какие проблемы вас ожидают и как их постараться обойти.
Начнём из далека, а именно — с типов дисков, которые бывают у виртуальных машин VMware.
- Thin — классические тонкие диски
- Lazy zeroed — если в блок не было ничего ранее записано, то записывается 0, потом идёт запись данных. Работает чуть быстрее, чем thin.
- Eager zeroed — диск заполняется нулями во время создания. Даёт самую высокую скорость работы, но требует значительного времени для создания.
Теперь же вернёмся к Veeam. В случае Thin дисков, восстановление Direct SAN в принципе не поддерживается. Только при помощи NBD или Appliance. Об этом чётко сказано в документации.
Lazy zeroed можно восстанавливать Direct SAN, НО процесс этот будет крайне медленным. Дело в том, что на самом деле Veeam работает с файловой системой через библиотеку VDDK. Veeam запрашивает выделение места под каждый блок данных, при этом постоянно ждёт подтверждения записи от VMware и сохраняет ещё и метаданные. Помимо этого, отправляет VMware запрос на предварительное зануление каждого выделенного куска пространства перед тем, как записать на него данные. И если сами данные ВМ у вас идет по SAN сети, то все запросы к VMware идут к API через менеджмент сеть.
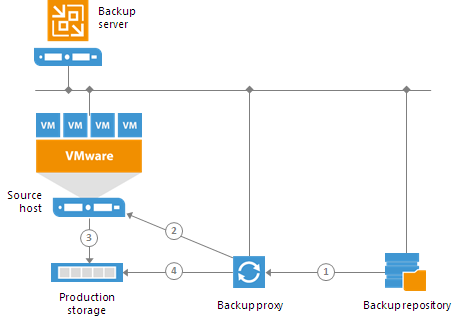
- The backup proxy sends a request to the ESX(i) host in the source site to restore data to a necessary datastore.
- The ESX(i) host in the source site allocates space on the datastore.
- Data blocks are written to the datastore.
Так что данная схема не совсем точна, т.к. данный процесс цикличен, а не единоразовый.
Даже сама VMware говорит: «SAN transport is not always the best choice for restores. It offers the best performance on thick disks, but the worst performance on thin disks, because of round trips through the disk manager APIs, AllocateBlock and ClearLazyZero.»
Почему с помощью всё того же VDDK нельзя выделять сразу весь объём — остаётся не ясным. При проблемах восстановления саппорт предлагает тестировать скорость работы с датастором при помощи VDDK и данные утилиты даже показывают вполне хорошую скорость.
Wrote 64 MBytes in 281 msec (227 MBytes/sec)
Но дело в том, что хоть саппорт и рекомендует данный процесс для теста, он не отражает действительности:
«Проведенный тест скорости является наиболее точным способом воспроизведения операций, происходящих при восстановлении, но, к сожалению, не может быть абсолютно точным. Так, обсуждаемая проблема с восстановлением lazy-zeroed дисков не воспроизводится этим тестом — при тесте мы просто записываем блоки данных, и не производим «зануления» (операции ClearLazyZero).»
По словам всё того же саппорта — по всей видимости, мы упираемся не в производительность отдельных компонентов, а в саму архитектуру VMware и те компоненты, которые используем Veeam для работы с системой виртуализации — VDDK.
Третий вариант — Eager zeroed. Но здесь проблема такая же, как и при создании Eager zeroed дисков — время. Да, скорость восстановления достигает более 300МБ/с, но на создание 500Гб диска требуется порядка 12 минут на SSD. Не во всех случаях это будет давать положительный результат, особенно если размер дисков виртуальной машины довольно большой.
Что же нам остаётся делать? Самое простое, что мы можем сделать быстро, и что даст результат — изменить блок, которым Veeam делает бекап машины и соответственно каким он восстанавливает. Находится это в разделе Storage optimization каждого задания.
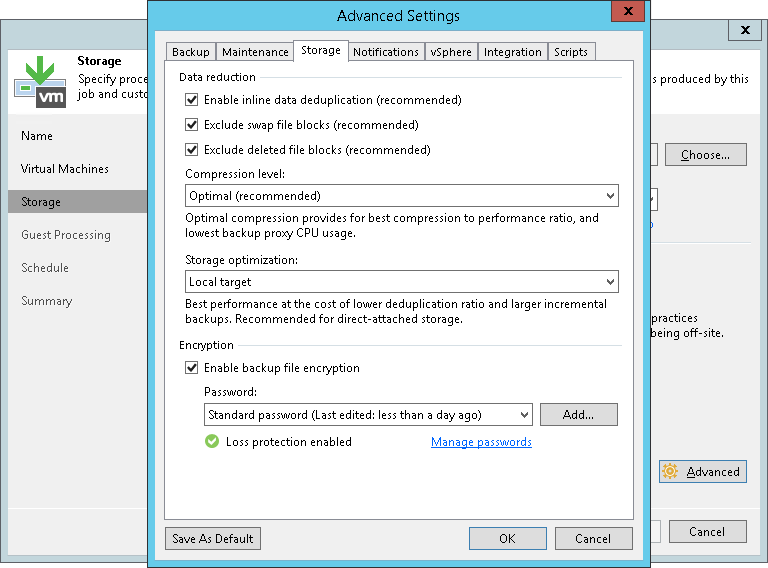
Вообще, насколько я лично понимаю этот экран настроек — делалась она для настройки дедупликации.
Нам доступно 4 режима:
- Local target (16 TB + backup files) — блок 4096 KB
- Local target — блок 1024 KB
- LAN target — блок 512 KB
- WAN target — 256 KB
Соответственно, чем больше блок, тем больше данных за одну итерацию мы передаём и тем меньше запросов на зануление мы отправляем, чем увеличиваем скорость восстановления. При этом, имеем обратный эффект для дедупликации — вероятность нахождения идентичного блока большого размера на много меньше, чем маленького, соответственно и эффективность от дедупликации будет ещё ниже (хотя стоит сказать, что дедупликация у Veeam пока и так не особо блещет своей эффективностью).
Есть ещё один вариант, он не совсем относится непосредственно к Veeam, он больше про регламент создания виртуальных машин. Не нужно делать большие диски. Когда у вашей виртуальной машины несколько дисков — вы имеете возможности восстанавливать их в несколько потоков. А как я уже говорил выше, проблемы с VDDK сказываются именно на высокой скорости на один поток. В таком случае виртуальную машину, объёмом, например в 5Тб, с 5х1Тб дисками мы можем восстановить в 5 раз быстрее, нежели с одним на 5Тб. Такие моменты стоит учитывать, если вы хотите добиться низкий показателей RTO.
В итоге, при помощи данных двух механизмов, нам удалось увеличить скорость восстановления в 7 раз, на VM с диском с данными на 4.2Тб с 26 часов до 4.
В качестве альтернативного варианта можно рассматривать HotAdd, если ваша сеть вам это позволяет. Но по нашим многочисленным тестам, производительность на поток в данном режиме у нас получилась примерно в 2 раза ниже, чем в режиме Direct SAN, с учётом того, что у нас 10Гб/с сети, и данный режим рекомендуется VMware в качестве наиболее производительного и предпочтительного.