Veeam + СХД: как не сделать себе больно
![]()
Пора вернуться к давно уже начатой теме — Veeam + СХД, старт которой я дал ещё в статье «Бекапы для начинающих: интеграция с СХД«. Но сегодня вы подойдём к этому вопросу с обратной сторону — с точки зрения СХД для хранения резервных копий, методов резервного копирования и дополнительных технологиях, которые позволяют нам как то ускорять процесс резервного копирования или экономии места под резервные копии.
Основной вопрос, который перед нами встаёт при планировании новой инфраструктуры (или при переходе старой инфраструктуры на Veeam) — какой метод резервного копирования мы планируем использовать. Проблема заключается в том, что все они создают довольно разную по своим характеристикам нагрузку на таргетную дисковую подсистему, что в свою очередь может очень сильно влиять на скорость резервного копирования и последующего восстановления.

Как вы видите из приведённой таблицы самый лёгкий вариант нагрузки — это классические полные бекапы и классические инкременты. Поэтому вариант фулл + инкременты, которые используются уже множество лет, наиболее лёгкая нагрузка для таргетной СХД (или дисковой подсистемы сервера) на классических HDD дисках. Мы имеем последовательную запись блоков на диски, что так же является более лёгкой нагрузкой на систему.
Почему я против дедупликации?
Здесь стоит немного отвлечься от самого Veeam и поговорить об СХД. В частности про такие системы как HPE StoreOnce и EMC DataDomain, да и в принципе любые системы с дедупликацией. Дело в том, что дедупликация превращает наши последовательно записанные данные в рандомные. Часть блоков, нами отправленные в последнюю сессию бекапа, заменяется на ссылки к более старым блокам, совпадающих с предыдущими копиями. С одной стороны в этом случае мы получаем очень высокую эффективность хранения данных, с другой стороны — ухудшаем время восстановления из резервной копии, т.к. при необходимости восстановиться из такой копии мы читаем данные не последовательно, а рандомно, т.к. нам нужно прочитать часть “старых” блоков от предыдущих копий которые располагаются в другом месте. А рандомное чтение всегда по скорости ниже, чем последовательное. Помочь в данном случае может только переход на flash, что пропагандируют некоторые компании, но многие ли могут себе позволить хранить бекапы на flash? Конечно такие есть, готовые платить за каждую сокращённую минуту RTO огромные деньги, но пока стоимость flash не так низка, как хотелось бы, поэтому такая возможность доступна далеко не всем. Именно по этой причине не рекомендую использовать HPE StoreOnce, EMC DataDomain и аналогичные системы или СХД с дедупликацией в качестве основного (первичного) репозитория для хранения резервных копий. Ведь в первую очередь мы должны обеспечить высокую скорость восстановления данных. Конечно это не «золотое» правило — есть компании кто не может позволить себе несколько хранилищ, а есть те, для кого «лишние 5-10 минут» не имеют значения. Всё зависит от вашего бизнеса с которым эти вещи должны быть согласованы и просчитаны. Но я отдаю предпочтение простым блочным хранилкам (хотя протокол доступа в данном случае не имеет значения) NetApp E-серии, которые не имеют механизма дедупликации и при этом прекрасно себя проявляют именно на операциях потокового чтения/записи.
Но и здесь, не все производители идут по одному и тому же пути. Есть на рынке и InfiniGuard от Infinidat. Можно воспринять это как минутку рекламы, но компания старается как раз решить те проблемы, о которых я говорил выше. InfiniGuard, являясь гибридной СХД она умеет предсказывать запросы данных. При любой записи, в том числе последовательной, СХД выстраивает векторы активности и запоминает, в каком порядке друг за другом шли данные. Даже после их дедуплицирования InfiniGuard хранит в оперативной памяти эти векторы активности. Как только сервер или агент резервного копирования начинает запрашивать данные из бэкапа, InfiniGuard, считав первые наборы со шпинделей, начинает предиктивно подгружать следующие последовательности данных в оперативную память и в дополнительный слой хранения в виде SSD. Такой подход позволяет приблизиться к flash по производительности, не настолько сильно повысив стоимость решения. Подробнее о данном решении можно посмотреть в вебинаре, который Infinidat проводил как раз вместе с Veeam. https://www.youtube.com/watch?v=twsuC9WIlAw
Но вернёмся к методам резервного копирования.
Сравнение 3 типов инкрементальных бекапов
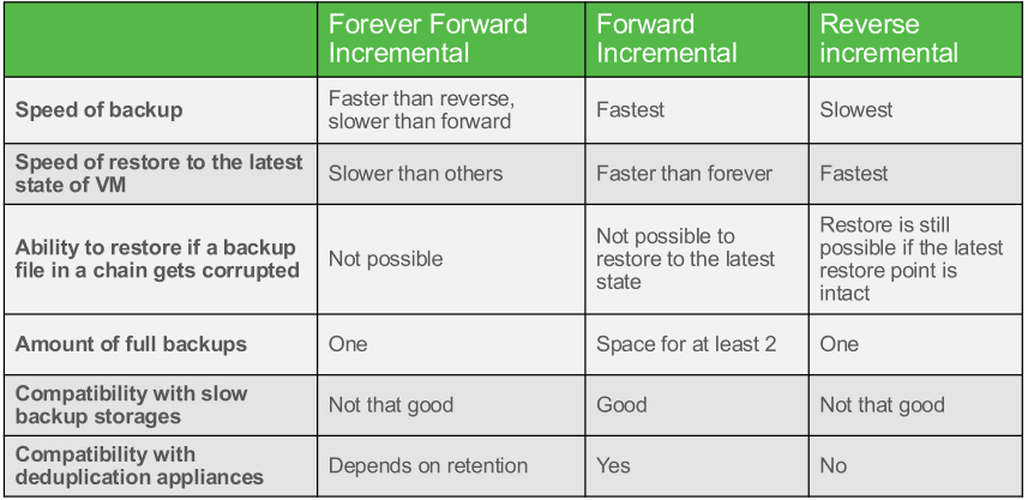
Под Slow backup storage не следует понимать что-то совсем старое — это вполне современные системы не обладающие десятками HDD, которые не могут похвастаться высокой производительностью на рандомных операциях чтения/записи, которые генерируются в тот момент, когда мы трансформируем бекапы в нашей цепочке.
Forward Incremental
Это как раз наш классический вариант инкрементального бекапа, который раз в неделю начинается с синтетической или полной резервной копии. Отдельно стоит сказать, что синтетический full бекап также создаёт дополнительную нагрузку, т.к. собирается из нескольких инкрементальных точек и, в данном случае, нам нужно решить, мы хотим иметь нагрузку на продуктивной системе (и у нас есть для этого окно бекапа), создавая классический full бекап, или мы готовы перенести её на СХД для РК и делать синтетический full.

Forever forward incremental
Хорош с точки зрения снижения нагрузки на продуктив и с точки зрения использования места, мы всегда забираем только инкременты и храним только инкременты, но бекапная цепочка не может состоять просто из инкрементов — первая точка в цепочке должна быть full. Соответственно при первом запуске задания мы всё равно сделаем full, а дальше будем делать инкременты, но что произойдёт, когда мы достигнем лимита цепочки в Х точек, определённых в настройках задания? На наш первый full мы будем накатывать второй инкремент

И, естественно, мы будем это делать каждый раз при каждом запуске. Отсюда у нас получается 1 запись нового инкремента, чтение инкремента из второй точки и запись этого в full первой точки.
Reverse Incremental Backup
Наиболее сложный вариант с точки зрения создания, ведь при каждом новом инкременте мы «вставляет» новые блоки данных в последнюю копию, чтобы всегда иметь последней точкой full копию. При этом изменившиеся блоки мы выделяем в «предыдущий» инкремент.

В качестве обратной стороны этого процесса мы всегда имеем full бекап последней точкой и, соответственно, это наиболее быстрый вариант с точки зрения восстановления данных.
Как происходит процесс трансформации точек у различных типов резервных копий можно с анимацией посмотреть в данной KB https://www.veeam.com/kb1932
Но вернёмся к синтетическим операциям которые на небольших дисковых системах являются крайне сложной нагрузкой. Кто-то может возразить — для их ускорения у нас есть ReFS/XFS, нам не нужно таскать блоки данных, при помощи API мы можем оперировать не блоками данных, а ссылками на них. В каких-то случаях это действительно работает (по моим наблюдениям — на небольших объёмах резервных копий). Но когда их размер становится действительно большим (я имею ввиду 10-ки ТБ), то тут всё становится грустно
Также не следует забывать, что в данном случае наш full будет состоять только из ссылок на блоки данных предыдущих инкрементов и здесь мы получаем ещё более худшую ситуацию, чем при дедупликации.
К чему я всё это говорю? Я лишь хочу заострить ваше внимание на том, что планируя среду резервного копирования, вы должны или заранее спланировать — какие методы вы будете использовать, чтобы корректнее подобрать оборудование для обеспечения приемлемых показателей RTO, либо, основываясь на уже имеющемся оборудовании, сделать правильный выбор в пользу тех или иных методов и технологий. Дело в том, что это крайне частая проблема с которой сталкиваются многие администраторы Veeam, и это крайне частый кейс в ТП.