Бекапы для начинающих: интеграция с СХД

Рассчитывая оборудование и ПО под новый проект, мне часто приходится рассказывать нашим менеджерам или менее опытным коллегам по цеху — что должно быть в данной системе для её максимальной эффективности. Сегодня я решил постараться описать данную идеальную схему, которая будет включать все компоненты, которые позволят сделать этот процесс более эффективным и менее влиятельным на продуктивные среды.Я постараюсь как можно подробнее описать всю эту схему от начала и до конца, а включать наш разговор будут следующие компоненты:
- ПО для РК
- Продуктивная СХД
- СХД для хранения РК
По ходу данной статьи я объясню, почему остановил свой выбор на конкретных решениях, на что следует обратить внимание при выборе продуктов и чем вы можете пренебречь, если у вас уже есть существующая инфраструктура, полное обновление которой не предполагается или вы ограничены в бюджете для реализации всех «фишек». Я не ставлю перед собой задачу уговорить вас на приобретение конкретных продуктов, я постараюсь объяснить — что из них даёт преимущества в процессе резервного копирования, чтобы вы могли самостоятельно определиться — какие из этих возможностей вам не нужны в принципе или от чего вы могли бы отказаться, чтобы уложиться в имеющийся бюджет или при постепенной модернизации текущей инфраструктуры.
На дворе 2018 год и большая часть инфраструктуры в любой компании — виртуализована. Поэтому говорить мы будем всё же о бекапе виртуальных машин. Начнём мы, пожалуй, с простого — как делается резервная копия виртуальной машины средствами какого-либо ПО или простого скрипта. Резервное копирование виртуальных машин, как на платформе VMware так и на платформе Hyper-V, осуществляется на базе снепшотов виртуальных машин. Снепшот – это снимок виртуальной машины на определённый момент времени с полным сохранением её состояния. И так, для того чтобы сделать резервную копию машины, наше ПО (или скрипт) должен дать команду гипервизору на создание снепшота виртуальной машины. При этом работа виртуальной машины продолжается, изменяющиеся данные пишутся в так называемый дельта файл, а данные в снепшоте не изменяются. Далее нам необходимо скопировать данные из снепшота в наше место для хранения резервных копий и выполнить удаление снепшота. Тут то и кроется основная проблема — чем дольше у нас существовал снепшот — тем больше данных записалось в дельта файл. А что такое удаление снепшота? Это процесс слияния изменённых данных в дельта файле с оригинальным файлом виртуальной машины (ведь данные в нём были неизменны, пока существовал снепшот и мы копировали из него данные). И этот процесс очень сильно влияет как на работу дисковой подсистемы, увеличивая на неё нагрузку, так и в целом на работу виртуальной машины. Отсюда можно сделать один вывод — чем быстрее мы делаем резервную копию, тем меньше у нас живёт снепшот и тем меньшее влияние он будет иметь на продуктивную виртуальную машину при удалении. И вот тут мы переходим к тому, чтобы могло нам помочь в этом. Во-первых, в VMware есть механизм Changed Block Tracking (CBT) (в версиях до Hyper-V Server 2016 у Microsoft не существовало подобного механизма и ПО для РК использовало собственные механизмы, с версии Hyper-V Server 2016 появился механизм Resilient Changed Tracking), который служит для того, чтобы отслеживать изменившиеся блоки данных виртуальной машины и записывает эту информацию в специальный файл, который умеет читать ПО для резервного копирования. После каждого бекапа этот файл обнуляется и соответственно при следующем запуске в неё будет информация только о тех блоках, который изменились с момента последней резервной копии. Это позволяет нам не копировать всю виртуальную машину, а только изменившиеся блоки данных (инкремент). Это уменьшает общий объём передаваемых данных и снепшот живёт меньше времени, а процесс резервного копирования выполняется быстрее. Но в этом механизме есть 2 проблемы:
- Очень частые жалобы на работу самого CBT, что она не всегда бывает корректной.
- Сам механизм инкрементальных бекапов не всегда надёжен, в нём могут быть ошибки, а при потере одного из инкрементальных бекапов в цепочке из нескольких, мы автоматически теряем и все следующие инкременты за ним, что делает невозможным восстановление виртуальной машины.
Но и делать каждый раз полную резервную копию не лучший выход с точки зрения нагрузки. И так — как же быть?
Для решения этих проблем ПО для резервного копирования научилось работать с продуктивными системами хранения данных, на которых располагаются наши виртуальные машины, а некоторые производители выпустили специализированные СХД для хранения резервных копий. И именно эта интеграция позволяет нам сделать бекапы более быстрыми, менее влиятельными на продуктивные системы и более надёжными.
Программное обеспечение для резервного копирования
Собственно, в нашем разговоре она будет являться ключевой системой, т.к. именно возможность интеграции ПО с оборудованием в данном случае является ключевым. А т.к. именно ПО для РК у нас является «оркестратором» процесса, то все возможности по интеграции должны им поддерживаться или предоставляться.
Большинство вендоров, из квадранта лидеров этого направления, имеют такие возможности в полном объёме: Commvault, Veeam, Veritas NetBackup, Micro Focus (ex-HPE) DataProtector, продукты EMC или IBM Spectrum Protect.
Есть и другие продукты на рынке, и на самом деле их ни мало, но не все они могут похвастаться столь широкими возможности. Почти все решения умеют ограничивать канал передачи данных, какие-то из решений могут работать с решениями для хранения резервных копий, но этого мало для нашей схемы.
Продолжать свой рассказ я буду с применением своих знаний и опыта по Veeam, тем более, что у них прекрасно структурирована документация, на которую можно дать ссылки для уточнений и есть отличная инфографика, которая поможет мне объяснить всё то, о чём пойдёт речь ниже.
Продуктивная СХД
Начнём с простого — использование физических серверов для резервного копирования. У разных вендоров они называются по-разному, у кого-то прокси, у кого-то агенты, суть одна. Мы будем получать данные с продуктивной СХД по физическим канал связи, даже если сам сервер резервного копирования у вас развёрнут в виде виртуальной машины в вашей инфраструктуре. Это позволит реализовать несколько вещей:
- Использование для резервного копирования SAN, без использования LAN
- Не использовать внутреннюю сеть между хостом виртуализации и виртуальной машины с сервером резервного копирования для передачи бекапов.
Таким образом, мы стараемся снизить нагрузку на наши продуктивные системы, в данном случае на сеть. Стоит обратить внимание, что раз мы используем SAN для передачи резервных копий — её производительность должна быть достаточна. Это позволит уменьшить нагрузку на продуктивную сеть LAN и систему виртуализации.
Второй и наиболее интересной возможность интеграции ПО для РК с продуктивными системами хранения данных является возможность использовать аппаратные снепшоты СХД. Что это нам даст? Это позволит снизить время жизни снепшота на стороне системы виртуализации. Как это работает? ПО даёт команду системе виртуализации создать снепшот виртуальной машины, а после ответа о готовности поступает следующая команда уже СХД — создать снепшот того тома, на котором располагается данная виртуальная машина, после получения ответа об успешном создании снепшота, отправляется следующая команда, снова системе виртуализации о том, что снепшот виртуальной машины можно удалить. В итоге у нас есть виртуальная машина, снепшот которой у нас хранится в снепшоте тома на стороне СХД. Далее этот снепшот монтируется к агенту/прокси системы РК и данные копируются уже с него. Тем самым мы снижаем время жизни снепшота виртуальной машины.
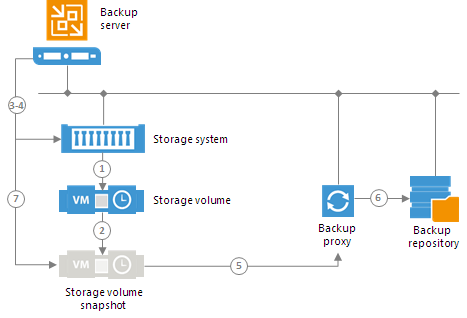
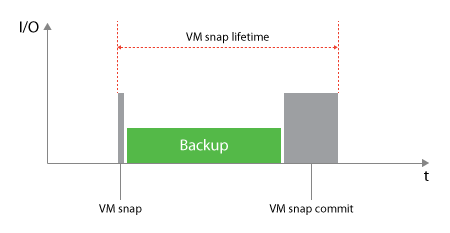 |
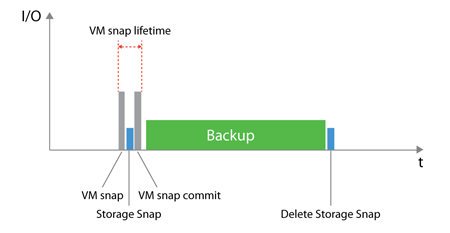 |
Данные две картинки иллюстрируют разницу между работой только со снепшотами VMware и снепшотами СХД.
Использовать снепшоты СХД — хорошо, но стоит помнить — не все снепшоты одинаково полезны. У разных вендоров, разные подходы к созданию снепшотов на стороне СХД, связанные с их архитектурой.
- CoW (Copy-On-Write) механизм создания снепшотов, возлагающий на СХД дополнительную нагрузку. При создании снепшота, чтобы старые блоки данных при изменении не затирались новыми, они копируются в специально выделенную область. Соответственно при изменении блоков данных, которые относятся к снепшоту, такой блок сначала копируется в выделенную область, а затем на его место записывается новый блок данных. Таким образом предотвращается повреждение данных внутри снепшота. Естественно все эти «паразитные» манипуляции с данными вызывают дополнительную нагрузку на СХД и по этой причине вендоры не рекомендуют использовать более десятка снепшотов, а на высоконагруженных томах не использовать их вообще.
- RoW (Redirect-on-Write) в данном случае, механизм записи немного иной, мы записываем изменённые блоки не на то же месте, где располагались оригинальные блоки данных, а в область, предназначенную для данных снепшота. Это позволяет уменьшить количество операций перезаписи, что делает снепшоты сами по себе менее влиятельными на СХД.
В итоге получается, что использование CoW не так уж и выгодно с точки зрения нагрузки, т.к. мы перенесём её с одной виртуальной машины на всю СХД и можем получить потерю производительность на множестве подсистем хранения (датасторов со стороны системы виртуализации). Использование же RoW снепшотов не подразумевает потерю производительности хранилища и как раз и позволяет снизить нагрузку на виртуальные машины, которые мы бекапим.
Третья возможность, предоставляемая нам интеграцией ПО с СХД — возможность контроля нагрузки на продуктивную СХД в момент резервного копирования. Вендоры подходят к этому вопросу с разных сторон, кто-то позволяет ограничить общую полосу пропускания трафика, кто-то позволяет на основе времени отклика тома снижать скорость передачи данных. В любом случае, эти механизмы позволяют снижать нагрузку на продуктивную среду и делать резервные копии не только в ночное, ненагруженное время работы СХД.
СХД для хранения резервных копий
С продуктивной СХД мы закончили, теперь переходим к системе, которая будет хранить наши резервные копии. Кто-то спросит — зачем покупать какой-то специализированный массив, если любое средство для резервного копирования и так умеет дедупликацию и компрессию? Это действительно так, но вопрос в эффективности этих процессов и в затрачиваемых ресурсах. Здесь сложилось 2 ситуации:
- ПО эффективно выполняет дедупликацию и компрессию, но при этом увеличиваются ресурсы, которые требуются серверу резервного копирования. Растёт потребность как в ядрах, так и в памяти и быстрой дисковой подсистеме.
- ПО не затрачивает больших ресурсов для выполнения данных операций, но при этом и эффективность его оставляет желать лучшего.
И здесь всё упирается в ваши объёмы инфраструктуры и политики хранения резервных копий. Если объёмы у вас не большие, а срок хранения копий не очень большой, то в целом эффективностью можно и пренебречь. С другой стороны, если у вас крупная инфраструктура и политикой компании требуется долговременное хранение копий (но тут могут помочь и дешёвые ленты) или просто объёмы очень большие, то разница между 1:2 и 1:4 — очень может быть существенна.
Около года назад я публиковал статью «Жим лёжа: сравниваем HPE StoreOnce и EMC Data Domain» и в рамках этой статьи проводил тест эффективности данных решений и сравнивал их с возможностями Veeam.
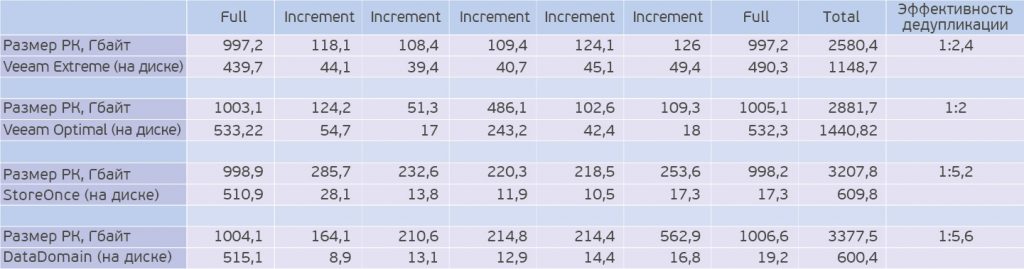
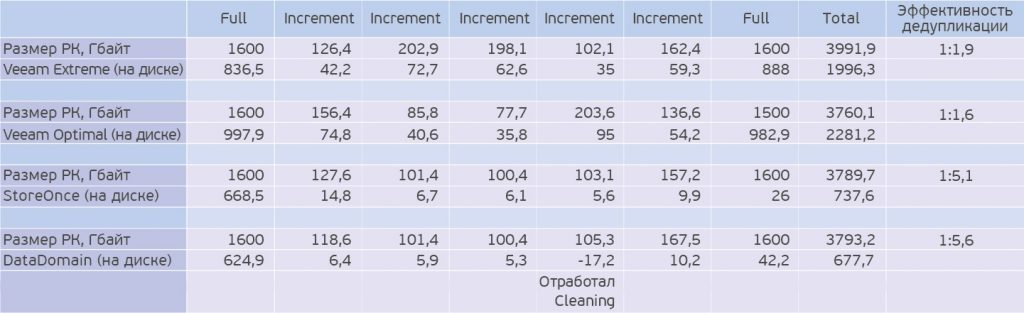
По данным тестам видно, что даже при максимальных настройках компрессии данных со стороны Veeam, его эффективность в более чем 2 раза хуже, чем у Dell EMC или HPE. Да, Veeam многим известен своей данной стороной с плохой дедупликацией, от вендора к вендору эта ситуация может менять как в лучшую, так и худшую сторону. Я не ставлю перед собой целью продать вам одно из этих решений, я лишь хочу обратить ваше внимание на эту ситуацию.
Следующим важным преимуществом решение от Dell EMC и HPE является наличие собственного протокола передачи данных — DDBoost и Catalyst соответственно. В чём их принципиальная особенность? Дедупликация данных проходит на стороне сервера, при этом серверу нет необходимости хранить информацию о блоках данных, находящихся на СХД и ему достаточно лишь вычислить хэш блока и спросить СХД о наличие у него блока с таким хэшем.
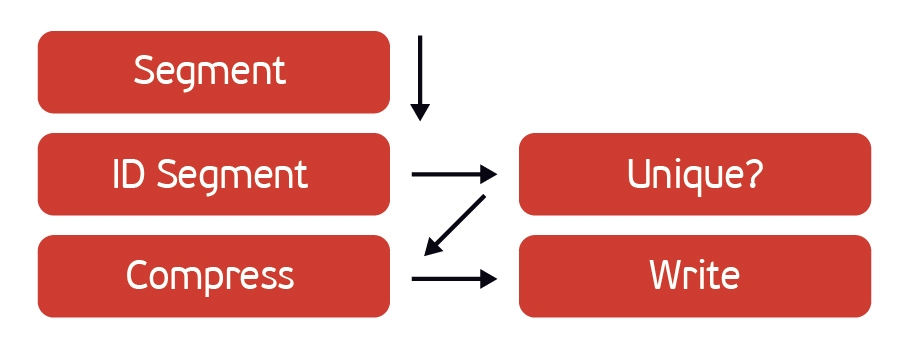
Если такой блок уже есть на СХД, система переходит к следующему, если нет, происходит его передача. С одной стороны — мы не нагружаем сервер резервного копирования тем, что хранить на нём данные о блоках, с другой стороны нам не нужно передавать все блоки данных, что бы дедупликацю выполняла сама СХД. В итоге за счёт этого мы уменьшает объём передаваемых данных, что положительно сказывает на всём времени процесса резервного копирования. Но стоит учитывать, что у этих систем есть и минусы. Например, у StoreOnce есть ограничение на количество точек восстановления в цепочке, которое для самой старшей системы 6600 — 42 на каждую ноду, а у более младших моделей ещё более низкие ограничения. Да и вообще список ограничений довольно большой, в отличие от того же Data Domain. Лично я по этим причинам предпочитаю именно второе решение. Есть и другие системы, такие как ExaGrid, Quantum Dxi и т.д., но их основной минус именно в отсутствии подобных протоколов передачи данных. В случае с Veeam, на нём устанавливается Data Mover, который отвечает за дедупликацию, передачу данных, сжатие и хранение данных. Здесь мы уже не получаем такого большого преимущества при передаче данных, но за то, мы получаем преимущества при трансформации бекапов, например, при Synthetic Full Backup, когда нам нет необходимости перемещать данные, а достаточно изменить лишь ссылки на них. Наличие Data Mover в данном случае ускорит данный процесс.
Вообще многие вендоры не рекомендуют использовать данные системы в качестве первичного хранилища резервных копий, а в большей степени для долгосрочного хранения, вместо ленточных библиотек. Связано это в первую очередь с тем, что данные системы нацелены больше на получение и хранение данных, нежели их восстановление. Если на классической блочной хранилке у вас есть возможность поставить SSD и настроить тиринг, что положительно скажется при Instant Recovery, то в случае с системами для хранение резервных копий — такой возможности нет, а сами системы не очень хорошо предназначены для работы на них виртуальных машин.
В данном тексте я не пытаюсь навязать вам своё мнение, относительно какого-то ПО или аппаратных решений, я хотел описать всю цепочку от и до, и как она могла бы выглядеть в идеальном мире. Вы же, основываясь на этой информации уже сможете самостоятельно для себя решить, какие из данных рекомендаций вы можете разумно реализовать у себя, а какие из них вас совершенно не волнуют. Но главное, что я хочу сказать — выбирая любое из решений в любом месте цепочки — очень подобно изучайте его, т.к. в каждом решении скрыты подводные камни и их все необходимо учитывать. Именно по этой причине я провожу очень много времени для развёртывания различных тестовых стендов, проведений тестирований и изучения продуктов не только по документации.
И желаю вам, что бы не приходилось ничего восстанавливать 🙂